
More CPUs Won't Find More Bugs: Insights from Combining LLM Agents and Jazzer
- Fabian Fleischer, Cen Zhang
- Post aixcc
- April 7, 2026
Table of Contents
When we were designing our CRS for the DARPA AI Cyber Challenge, we quickly realized that scaling Jazzer alone wouldn’t be enough for Java vulnerability discovery. The hard vulnerabilities required structured, semantically meaningful inputs that random mutation couldn’t produce. So we built Gondar, a system that combines LLM agents with coverage-guided fuzzing, and it helped us win.
After AIxCC, we wanted to put this to the test: how well does the approach hold up under rigorous, controlled evaluation? The resulting paper will be published at IEEE S&P ‘26. This post is about our journey and what we found along the way.
We Started by Throwing Compute at the Problem
The conventional assumption in fuzzing is straightforward: more compute, more bugs. So we tested it. We ran Jazzer, the state-of-the-art coverage-guided Java fuzzer, in two configurations: a standard baseline with 3 cores and 12 hours per target, and a large-scale run with 50 cores and 24 hours per target, over 7.2 CPU-years of total computation.
No existing Java vulnerability benchmark suited our needs, so we built one: 54 vulnerabilities across 22 open-source Java projects, spanning 12 CWE types. It draws from real CVEs (19), AIxCC challenges (20), and vulnerabilities we manually injected based on real-world patterns (15). Controlled access is being prepared to support reproducibility while mitigating model contamination.
Both configurations exploited exactly 8 vulnerabilities. Scaling compute by 17x and doubling the time budget found zero additional vulnerabilities. The large-scale run reached 3 more sinks (29 vs. 26), but couldn’t convert any of them into a working exploit.
Why? The failures fell into two categories: 46% of vulnerabilities were never even reached, and another 39% were reached but not exploited, what we call the “last-mile” problem. These vulnerabilities require inputs with specific structure and semantics that random mutation is unlikely to produce. A deserialization exploit needs a valid archive with correct internal structure. A path traversal needs paths that bypass sanitization logic. An XXE attack needs well-formed XML with specific entity definitions. A command injection might depend on satisfying a cryptographic check. Random mutation won’t solve these; they require understanding what the code expects and why.
Half the targets reached 95% of their final coverage within 15 minutes (Figure 1). The remaining hours and cores contributed almost nothing. This isn’t a resource gap. It’s a semantic gap.
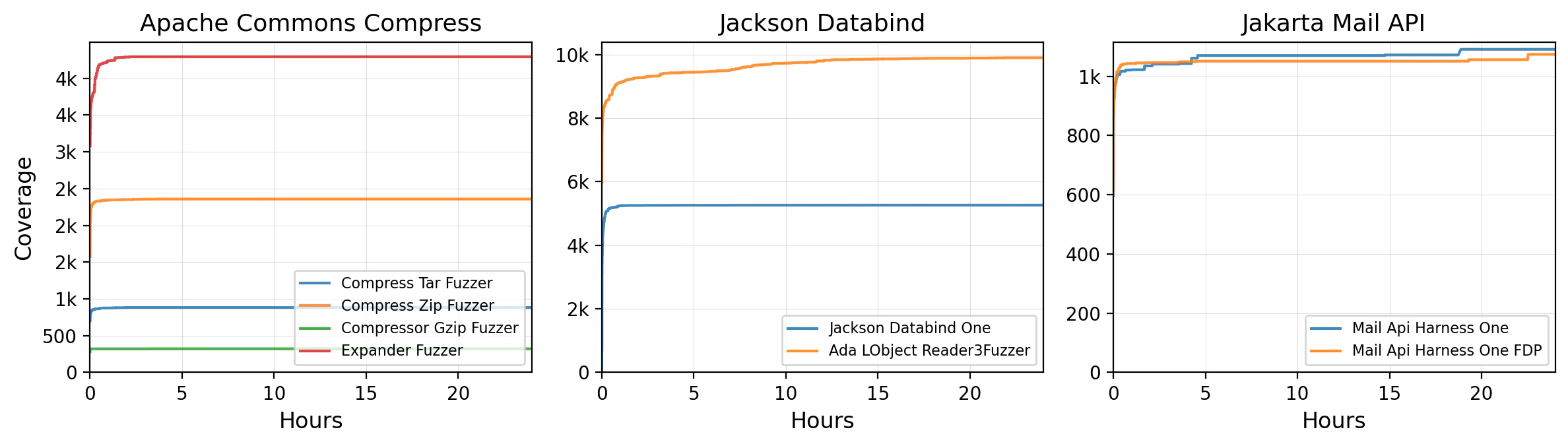
Figure 1: Jazzer’s code coverage over time for three example projects. Each line is a fuzzing harness. Coverage flatlines early; the remaining hours contribute little new coverage.
So We Added Semantic Reasoning
Since more compute wasn’t the answer, we needed something that could reason about code structure. We set out to combine LLM-based agents with Jazzer, targeting sinks: security-sensitive API calls like Runtime.exec(), ProcessBuilder, or SQL query methods where vulnerabilities actually manifest. We’ve written about this sink-centered approach before in the context of Atlantis-Java.
Key to the sink-centered design are three agents assisting in vulnerability detection (see Figure 2), one during static analysis and two during dynamic testing.
The first agent sits inside Gondar’s static sink detection module, which applies CodeQL to identify potential sinks. However, CodeQL’s built-in queries filter sinks based on predefined source definitions, which are too restrictive for our use case: attacker-controlled input comes from fuzzing harnesses, not the sources CodeQL expects. So we strip CodeQL’s filters and use only its sink definitions, extracting all call sites directly. This gives us thousands of candidates, most of which are false positives. We reduce these with our own filtering pipeline including both traditional static analysis (constant value checks, reachability checks) as well as our exploitability assessment agent, which filters out sinks that it determines unexploitable based on concrete evidence in the source code. This allows Gondar to bring the number of sinkpoints down to a few hundred actionable sinks while retaining over 96% of the truly exploitable ones.
Second, a sink exploration agent analyzes call paths from the program entry point to each sink, reads the source code along the path, and generates inputs designed to satisfy the constraints needed to reach it. Third, a sink exploitation agent receives inputs that successfully reach sinks (we call these “beep seeds”) and iteratively develops proof-of-concept exploits by reasoning about the vulnerability-specific conditions needed to trigger Jazzer’s sanitizers.
Critically, these agents don’t run in isolation. They operate concurrently with Jazzer and exchange artifacts in both directions: exploration seeds flow into the fuzzer’s corpus for further mutation, while discovered beep seeds flow to the exploitation agent as concrete starting points. All exploitation outputs, even failed attempts, are fed back to the fuzzer, which may mutate a near-miss into a working exploit.

Figure 2: Gondar’s architecture. LLM agents and the fuzzer run concurrently, exchanging artifacts bidirectionally. Exploration seeds enrich the fuzzer’s corpus; discovered beep seeds ground the exploitation agent’s reasoning.
Putting Gondar to the Test
We ran Gondar on the same 54 vulnerabilities. Figure 3 shows vulnerabilities reached versus exploited across all 15 configurations: 7 Gondar model variants, 3 ablations, and 5 baselines. Upper-right is better.
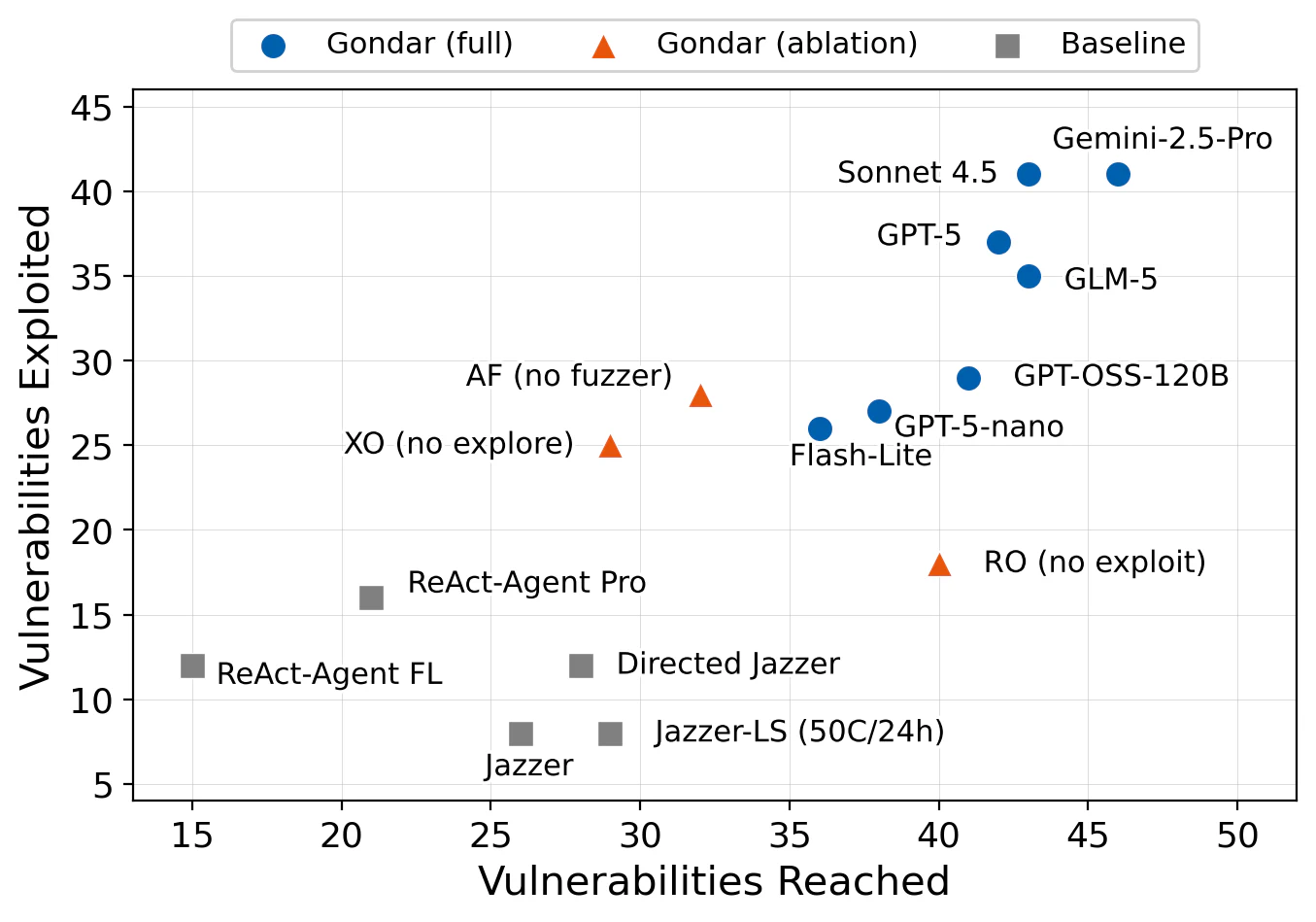
Figure 3: Vulnerabilities reached vs. exploited for all configurations. Gondar configurations (blue) cluster in the upper-right; baselines (gray) sit in the lower-left. Ablations (orange) show the impact of removing individual components.
Gondar exploits 41 of 54 vulnerabilities with its best configuration (Gemini-2.5-Pro), compared to Jazzer’s 8. That’s over 5x as many on the same benchmark, at comparable or lower cost. Even the cheapest Gondar configuration (GPT-5-nano at $182 total) exploits 27 vulnerabilities, still over 3x the baseline.
The ablations confirm that each component matters: removing the exploration agent (XO) drops reached vulnerabilities from 42 to 29; removing the exploitation agent (RO) drops exploited from 37 to 18. Gondar also exploits 35 of the 46 vulnerabilities that Jazzer misses, by leveraging LLM reasoning to satisfy constraints that mutation alone cannot.
The paper digs deeper into each stage: how sink filtering balances precision and recall, how iterative refinement drives exploitation success, and how Gondar compares against static analysis tools like CodeQL and SpotBugs. But two things surprised us most.
Takeaway 1: LLMs and Fuzzers Are Complementary, Not Interchangeable
It’s tempting to think of LLMs as a replacement for fuzzers, or vice versa. Our results show the opposite: they have fundamentally different strengths, and the combination is greater than the sum of its parts.
LLMs excel at structure and intent. They can generate a well-formed ZIP archive containing a crafted payload, reason about path constraints from source code, or construct an XML document that satisfies a parser’s type system. Fuzzers excel at fast mutation, exploring millions of input variations per second. Neither capability substitutes for the other, and our data confirms it: 7 vulnerabilities in our benchmark are found only through the agent-fuzzer collaboration. Neither the agents alone nor the fuzzer alone discovers them.
Take a zip-slip vulnerability in Apache ZooKeeper: the exploitation agent understands the vulnerability pattern and generates archive inputs that are structurally close to a working exploit, but not quite right. Jazzer picks up these seeds and mutates them, eventually producing an input that triggers the sanitizer. The agent provides the semantic scaffolding; the fuzzer provides the final refinement.
Takeaway 2: Open-Source Models Deliver Near-Flagship Performance
After seeing these results with flagship models (GPT-5, Gemini-2.5-Pro, and Claude Sonnet 4.5, which exploit 37-41 vulnerabilities at ~$2,400-$3,100 total), we asked the natural follow-up: how much does the model actually matter?
We swapped in GLM-5, an open-source model, and the result surprised us. GLM-5 exploits 35 vulnerabilities at a total cost of just $392, or $11.21 per bug, compared to $66-$74 for flagship models. It achieves 85% of flagship performance at roughly 13-16% of the cost.
Put differently: GLM-5 at $392 finds more vulnerabilities than large-scale fuzzing at $3,264, while costing less than one-eighth as much (Figure 4). The architecture amplifies the model. A well-designed system with a modest open-source model beats brute-force compute with no intelligence.
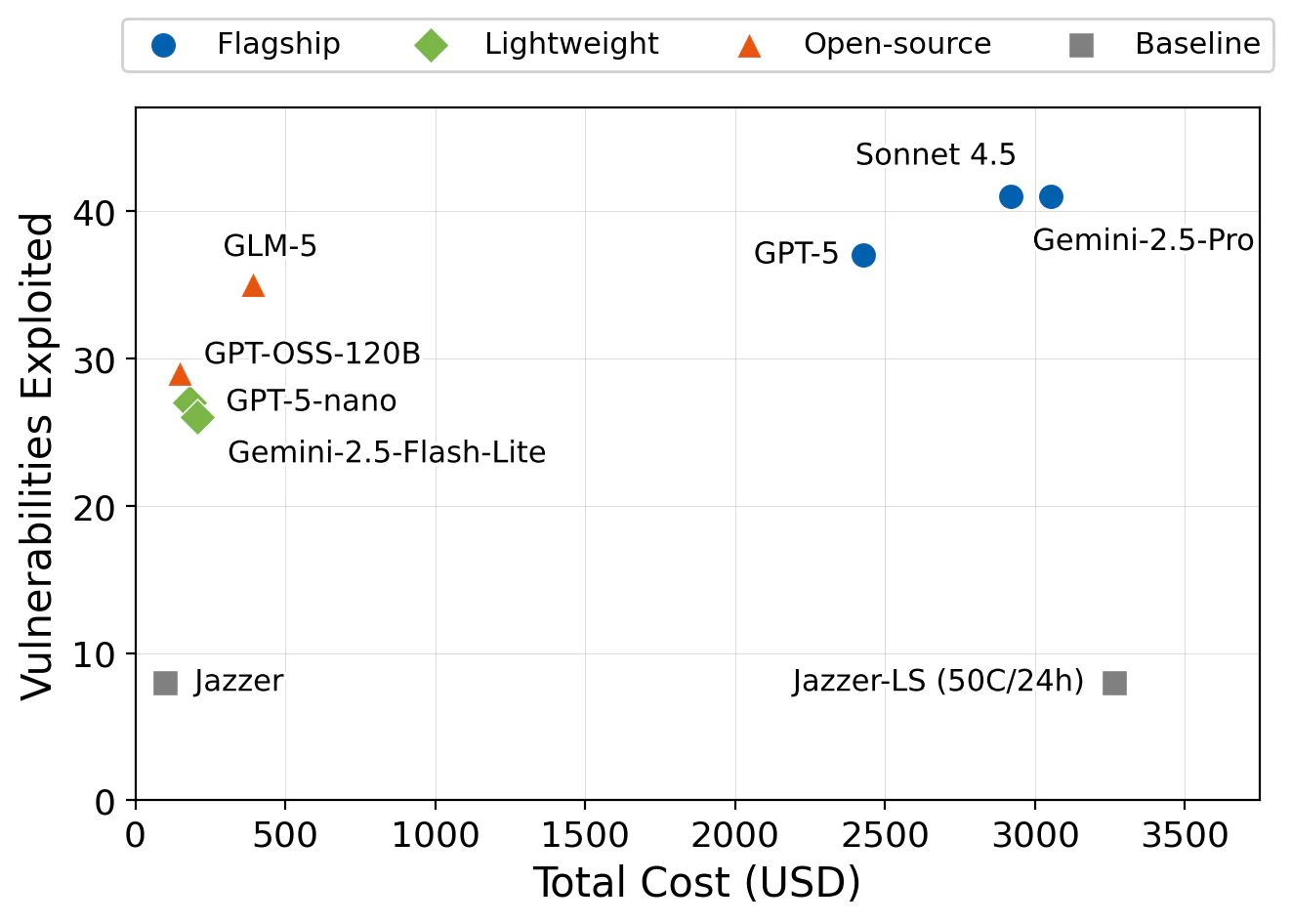
Figure 4: Cost versus vulnerabilities exploited across all configurations. GLM-5 sits in the sweet spot: near-flagship effectiveness at a fraction of the cost. Large-scale fuzzing (Baseline-LS) costs the most while finding the fewest vulnerabilities. The GLM experiment was supported by FriendliAI.
Closing Thoughts
These results come from our controlled benchmark for a reproducible, scientific evaluation, but Gondar has found real bugs too. During AIxCC, it discovered 3 zero-day vulnerabilities in real-world projects (Hertzbeat, Healthcare-Data-Harmonization, and PDFBox), all responsibly disclosed. It’s now part of OSS-CRS, an OpenSSF Sandbox Project for continuous open-source security protection, where it has already found another zero-day path traversal in a widely used Java database.
When we started building Gondar for AIxCC, we knew fuzzing alone wasn’t enough. Now we have the numbers to back that up: adding sink-focused agents finds at least 3x more bugs than spending multiples on raw fuzzing alone, even with a cheap open-source model. Check the paper for full details.
References
- Gondar paper - Full paper with detailed methodology and evaluation
- Implementation - Source code of Gondar
- Jazzer - Coverage-guided fuzzer for Java
- CodeQL - Semantic code analysis engine
- DARPA AIxCC - AI Cyber Challenge competition
- OSS-CRS - Open-source Cyber Reasoning System platform


