Patching Vulnerabilities with Coding Agents in 2026
- Cen Zhang, Andrew Chin, Brian Lee, Dongkwan Kim, Fabian Fleischer, Youngjoon Kim, Jiho Kim, Taesoo Kim
- Post aixcc
- March 11, 2026
Table of Contents
LLM-based patch generation has become a practical approach to fixing software vulnerabilities. Tools like Codex, Claude Code, and Gemini can read code, reason about bugs, and produce patches — often in seconds. But how well do they actually perform, in 2026?
To find out, we (Team Atlanta folks at Georgia Tech) tested 10 agent configurations — combining four agent frameworks with five frontier models — on 63 real crashes from the DARPA AIxCC final competition.
Experiment Setup
Evaluation Task
Given a code repository (with oss-fuzz build tooling), a crash-triggering input, and the corresponding crash log, each agent must produce a patch that fixes the underlying vulnerability. The agents run with their default settings — no custom prompts, no task-specific tuning. They are free to explore the codebase, read files, and use any default tools available in their framework. Each agent framework (Claude Code, Codex CLI, Copilot, Gemini CLI) provides its own agentic workflow for code retrieval, reasoning, and tool orchestration, while the underlying LLM model handles the core patch reasoning.
Each agent gets up to three attempts per crash. After each attempt, the patch is automatically validated: applied, compiled, tested against the project’s existing test suite, and replayed against the crash-triggering input. If any step fails, the error output is returned to the agent for another try.
Dataset
Our benchmark consists of 63 crashes across 24 open-source projects (14 C and 10 Java), based on synthetic vulnerabilities from the DARPA AIxCC final competition (in public release procedure).
Agent Frameworks
We evaluate 10 agent configurations spanning four agent frameworks and five frontier models, all using their latest versions as of February 2026. Each framework pairs with one or more models. Among them, Copilot supports multiple model backends, which allows us to test the same framework across different models. When a framework runs its own vendor’s model (e.g., Claude Code with Opus, Codex CLI with GPT), we call it a native configuration; when Copilot runs another vendor’s model, we call it non-native.
| Framework | Opus 4.5 | Opus 4.6 | GPT-5.2 Codex | GPT-5.3 Codex | Gemini 3 Pro |
|---|---|---|---|---|---|
| Claude Code v2.1.25 | yes | yes | — | — | — |
| Codex CLI v0.98.0 | — | — | yes | yes | — |
| Gemini CLI v0.28.2 | — | — | — | — | yes |
| Copilot v0.0.406 | yes | yes | yes | yes* | yes* |
* Copilot was updated to v0.0.409 during evaluation.
Classification
All patches passing automated validation are then manually reviewed (yes, we went through all 630 generated patches by hand, and cross-validated 456 of them :D). A patch is classified as semantically incorrect if it suppresses the crash but introduces a new bug or unexpectedly alters program functionality. In total, we classify each outcome into three categories:
| Outcome | Description |
|---|---|
| Valid | The patch correctly fixes the vulnerability. |
| Invalid | The patch fails compilation, tests, or crash replay. |
| Semantically Incorrect | The patch passes all automated checks but does not correctly fix the vulnerability. |
Due to this manual effort, each configuration was run only once — our goal is not a fully rigorous experiment controlling for randomness and repetition, but rather to understand the latest trends in agent patching capability while keeping the evaluation effort manageable.
Q1: How Well Do Today’s Agents Patch Zero-Day Vulnerabilities?
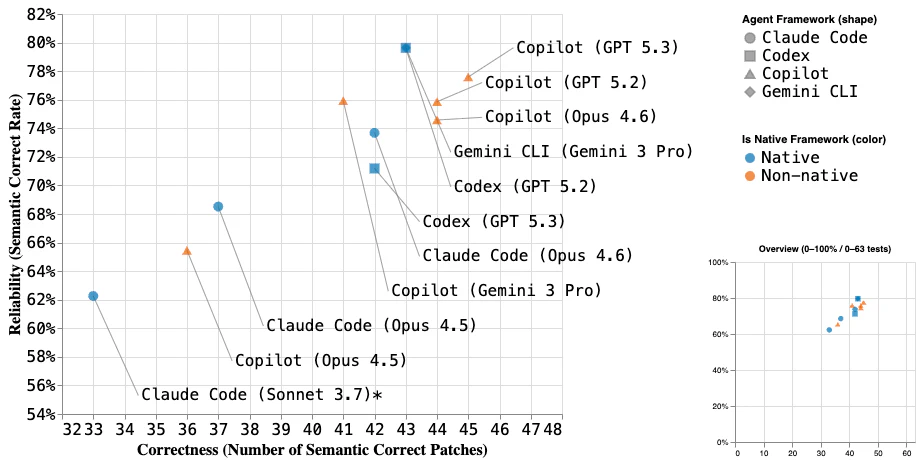
* Claude Code with Sonnet 3.7 data (the bottom-left one) is from the AIxCC SoK paper.
Steady Progress from ‘25 to ‘26
The SoK study on AIxCC evaluated Claude Code v1.0.88 with Claude 3.7 Sonnet on the same 63 vulnerabilities, producing semantically correct patches for 33 out of 63 crashes (~52%) with a semantic correctness rate of ~62%. We kept the same evaluation setting in this blog, making this a direct 2025 baseline.
Fast forward to early 2026: the best configurations now reach ~45 out of 63 (~71%) in correctness and ~80% in semantic correctness rate, while even the weakest covers ~36 (~57%) with ~60% reliability. This reflects the continued and rapid improvement in LLM/agent capabilities from 2025 to 2026, which is amazingly fast and as stable as we’ve seen in the past years.
It’s worth noting that this benchmark is designed around coverage of diverse, real-world open-source projects and vulnerability types, rather than a collection of intentionally difficult patch scenarios. Higher correctness here means the agents can handle a broader range of real-world vulnerability scenarios. We do not dive into individual patch cases or AIxCC challenge details here; for per-vulnerability analysis, refer to the paper’s Section 7.
Model Choice Outweighs Framework Choice
Across our ten 2026 configurations (distinguished by shape for framework and color for native vs. non-native), the choice of model has a larger impact than the choice of agent framework. The most notable model-level difference is from Opus 4.5 to 4.6, which shows a clear jump in both correctness and reliability. Other model gaps are smaller — GPT 5.2 and 5.3 are close overall, and Gemini 3 Pro lands in a similar range with a tendency toward higher reliability.
The choice of agent framework also shows some interesting patterns. Since Copilot supports multiple model backends, we can directly compare it against each model’s native agent (Claude Code, Codex CLI, Gemini CLI). In the figure, blue dots mark native framework configurations and orange dots mark non-native ones (i.e., Copilot with another vendor’s model). A native framework often does not lead to better performance — the orange dots frequently land above or to the right of their blue counterparts. For example, Copilot + GPT 5.3 outperforms Codex CLI + GPT 5.3, and Copilot + Opus 4.6 outperforms Claude Code + Opus 4.6, in both correctness and semantic correctness rate. However, the framework-level differences are generally smaller than the model-level ones, typically within just a few patches. This is expected for our evaluation scenario — agentic code search followed by patch reasoning — where the model’s core reasoning capability dominates, and other framework strengths (broader tool capabilities, usability, developer experience) play a lesser role.
The 20–40% Semantic Incorrectness Gap
Even the best configuration has ~20% of its patches be semantically incorrect — they pass all automated validation but are actually wrong. This is the most dangerous failure mode: invisible to automation, and only catchable by manual review.
To understand why patches fail semantically, we manually analyzed all 145 semantically incorrect patches across 34 vulnerabilities and identified several recurring patterns. Note that a single patch can fall into more than one category, so the counts below sum to more than 145:
- Functionality altered or broken (55 entries) — The most common issue. The patch fixes the bug but changes normal program behavior in unintended ways. For example, several agents correctly added a null check but also inserted an early return that skips subsequent processing, altering the function’s semantics.
- Patch the symptom instead of root cause (38 entries) — The patch suppresses the crash without properly addressing the underlying defect. For example, agents reset a dangling pointer at the crash site rather than adding proper null initialization in the common API where the pointer should have been set — the root cause remains, just not triggered in this call path. For memory overflow bugs in particular, agents tend to apply defensive patches that lack true root-cause tracing: enlarging a buffer to prevent an overflow instead of fixing the off-by-one miscalculation, or doubling an allocation that then silently reads garbage data.
- Incomplete or insufficient guard (28 entries) — The patch targets the right defect but the guard condition is too weak or a necessary check is missing. For example, some agents added a
buffer.remaining()check to prevent oversized allocations, but the threshold was not strict enough — huge allocations were still possible. - Wrong API or type usage (15 entries) — The patch uses a function or type whose result carries different trust assumptions. In a Wireshark-based challenge, the vulnerability stemmed from trusting
tvb_reported_length— a packet-supplied value fully controlled by the attacker — to size a buffer operation. Many agents kept relying on this untrusted API in their patches, failing to understand the proper usage and trust boundary of the API — that its return value is attacker-controlled and cannot be safely used for memory operations. - Wrong security mitigation strategy (15 entries) — The patch applies a problematic mitigation strategy to certain vulnerability types. In a Log4j2 vulnerability variant, many agents chose to whitelist certain protocols for JNDI lookups, when the correct fix is to disable JNDI lookup entirely.
- Controversial (4 entries) — Reviewers disagreed on whether the patch is semantically correct. These are cases where the patch is reasonable but imperfect — not clearly wrong, but not clearly right either. Different developers may judge it differently.
Q2: Can We Improve Semantic Correctness?
Semantic incorrectness is hard to eliminate at the single-agent level — even the best model still produces a meaningful number of semantically incorrect patches. So we asked: if we generate patches from multiple agents, can we pick a better one?
Approach: Ensemble by Selection
The idea is simple: run multiple agent/model combinations on the same vulnerability, collect all patches that pass automated validation, and select the best one. The selector has no additional guidance — it only knows that these patches passed automated tests and may still have issues like semantic incorrectness or incomplete fixes. It must pick the one most likely to be correct, purely from the candidates themselves. A nice property of this setup is that we can evaluate it directly against our existing manual validation — no new manual review is needed, since we already know which patches are semantically correct. We use Copilot v0.0.409 with GPT-5.3 Codex for all ensemble experiments.
Results
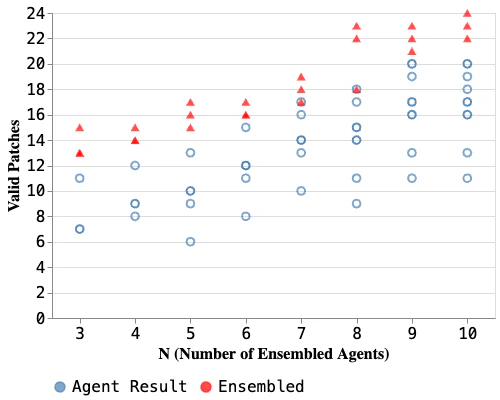
The left figure focuses on vulnerabilities with at least one semantically incorrect patch — the cases where selection actually matters. For each N (3–10), it compares the number of valid patches from individual agents (blue) versus the ensemble (red). Since different N values require different numbers of candidates, the set of eligible vulnerabilities varies. For almost all values of N, the ensemble outperforms every single agent — only a couple of cases (N=7, 8) tie with the best individual.
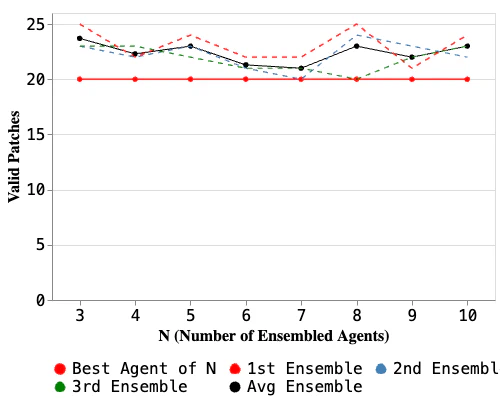
The right figure includes all vulnerabilities (not just those with semantically incorrect patches) and compares the total ensemble result (across multiple trials) against the best single component. The ensemble consistently matches or outperforms the best component, confirming that selection helps on the hard cases without hurting the easy ones. On average, N=3 delivers the best ensemble performance — one trial at N=8 edges ahead by a single patch, but adding more candidates beyond 3 doesn’t reliably help, while the computational cost scales linearly. This makes N=3 the practical sweet spot.
Why Does It Work?
Intuitively, when multiple agents produce different patches for the same vulnerability, the contrast between them is informative. A correct patch might fix the root cause cleanly, while an incorrect one only suppresses the crash or over-engineers the fix — adding redundant checks, touching unrelated code, or taking a convoluted path where a simpler alternative exists. When the selector sees these candidates side by side, the better patch tends to stand out.
OSS-CRS Integration
Beyond this evaluation, we have also implemented all the patch agents and the ensemble selector as open-source components in the OSS-CRS platform (see References for links to individual repos). These are clean reimplementations built for the OSS-CRS architecture, not direct ports of the code used in this evaluation. As coding agents continue to improve, we plan to keep these components up to date — interested readers can try them out directly, and we hope they benefit the broader open-source security community.
Note: The detailed benchmark data and per-vulnerability results are currently in the process of being made public, as they involve AIxCC final competition challenge details. We will update this post with full data once the release is complete.
References
- SoK: DARPA’s AI Cyber Challenge (AIxCC) — Systematic analysis of AIxCC competition design, CRS architectures, and results
- OSS-CRS — Open-source platform for orchestrating bug finding and patch agents
- crs-claude-code — Claude Code-based patch agent
- crs-codex — Codex-based patch agent
- crs-copilot-cli — Copilot CLI-based patch agent
- crs-gemini-cli — Gemini CLI-based patch agent
- crs-patch-ensemble — Ensemble selection for patch candidates
Contributors
This work is a joint effort by Team Atlanta members at Georgia Tech.
- Experiment design: Taesoo Kim, Cen Zhang
- Experiment implementation & execution: Cen Zhang, Andrew Chin, Youngjoon Kim, Dongkwan Kim, Brian Lee
- Manual & cross validation: Andrew Chin, Fabian Fleischer, Brian Lee, Jiho Kim, Cen Zhang, Dongkwan Kim, Youngjoon Kim
- Analysis & writing: Cen Zhang
- OSS-CRS integration: Dongkwan Kim, Cen Zhang, Andrew Chin