
Teaching LLMs to Retrieve: Custom Models for Security Patch Generation
- Minjae Gwon, Sangdon Park
- Atlantis patch
- November 2, 2025
Table of Contents
The Typedef That Changed Everything
Picture this: you’re asking an LLM to patch a security vulnerability in Nginx, a codebase with millions of lines. The bug is clear, the fix location is obvious, but your patch won’t compile. Why? Because buried somewhere in the headers are two critical typedef definitions that the LLM never saw.
We discovered this the hard way during the AIxCC Semifinals. Challenge challenge-004-nginx-cp/cpv15 became our wake-up call. When we ran our baseline patching agent Aider 20 times without the typedef definitions, only 5 patches compiled successfully. But when we included those typedefs? 18 out of 20 compiled successfully. That 5/20 → 18/20 leap wasn’t about smarter LLMs or better prompts. It was about giving the right context.
This insight inspired the design of an our agent (i.e., the Multi-turn Retrieval Agent) and a deeper question: instead of hand-crafting context, could we teach an LLM to learn what context really matters on its own?
From Engineering to Learning
Context engineering works—as we showed in our previous post, systematic information structuring dramatically improves LLM performance. But context engineering has a problem: it’s manual, heuristic-driven, and doesn’t scale across different bug types and codebases.
Human developers don’t patch bugs in one shot. They form hypotheses, examine code, run tests, gather clues, refine their search. They learn what context matters through iteration. Why shouldn’t our AI do the same?
This insight led us to develop custom models for code context learning—specialized LLMs trained through reinforcement learning to identify and retrieve the missing pieces needed for successful patch generation.
The Problem: Context Windows Meet Reality
Let’s be brutally honest about the challenges:
- Context Window Limitations: Even with today’s long-context models, you can’t feed an entire large-scale codebase into an LLM. The attention complexity and window size limits make it infeasible. A typical enterprise codebase might have 10 million lines—good luck fitting that into a 200K token context window.
- API Costs: Processing massive inputs isn’t just technically difficult—it’s financially prohibitive. Repeatedly sending thousands of lines to GPT-4 or Claude for every patching attempt would bankrupt most security budgets faster than you can say “vulnerability.”
- The Missing Context Problem: But here’s the real challenge—you need just enough context for the patch to work, but not so much that you overwhelm the model or your wallet. Too little context and your patch won’t compile. Too much and you waste tokens on irrelevant code.
How do we find that sweet spot? We treat it as a learning problem.
Code Context Learning: The Setup
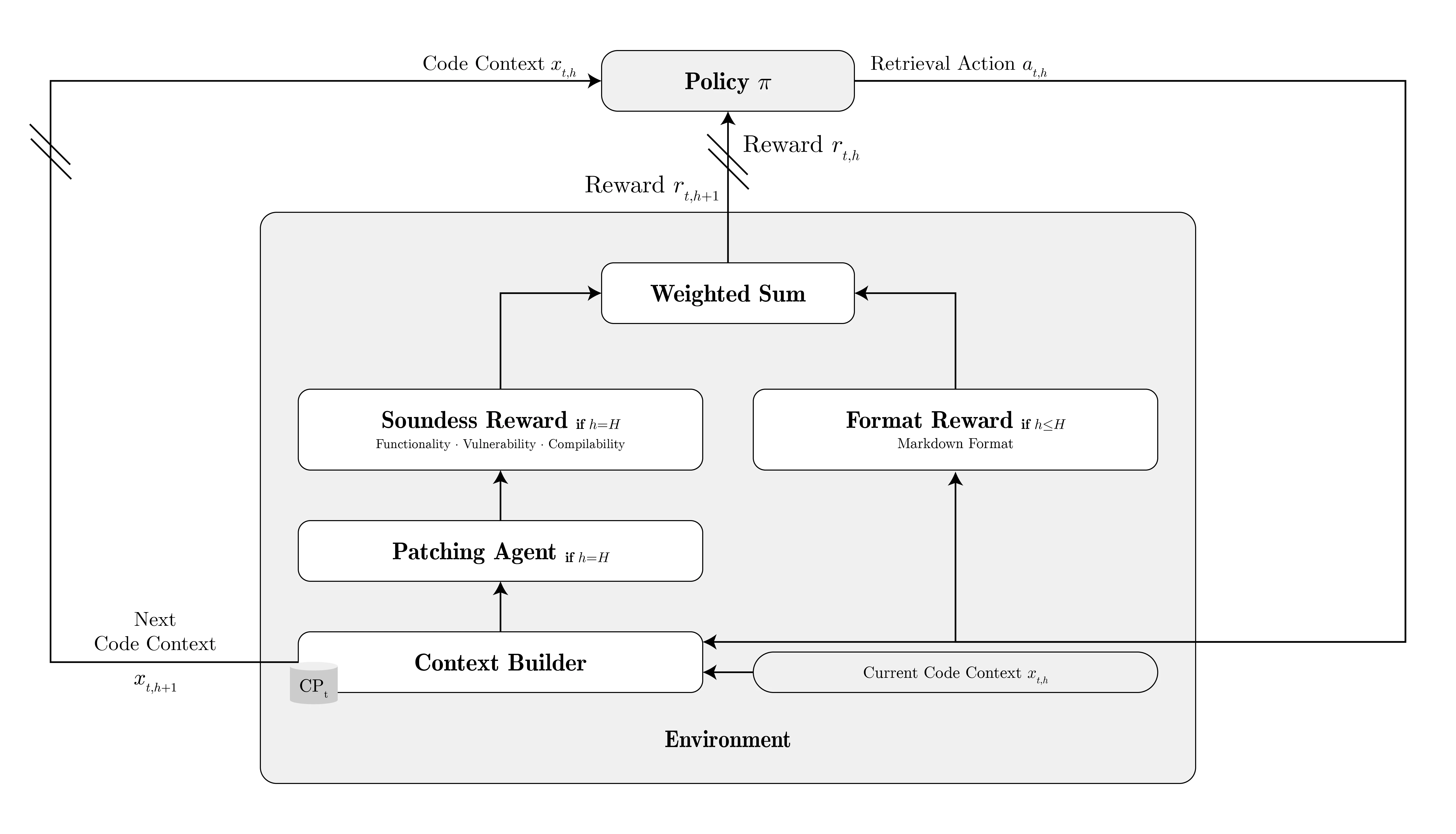
We formulated code context learning as a reinforcement learning (RL) problem. Here’s the intuition:
- The Environment: A codebase with a vulnerability and a crash log
- The Agent: Our custom LLM that decides what code to retrieve
- The Actions: Retrieving specific code symbols (functions, structs, types)
- The Reward: Whether the generated patch compiles and fixes the vulnerability
At each turn $h$, the agent observes the current context $x_{t,h}$ and chooses retrieval actions $a_{t,h}$—requests to fetch specific code definitions. The environment integrates these retrieved artifacts into the context, constructing the next state $x_{t,h+1}$.
After $H$ turns of retrieval, we feed the final context to a powerful general-purpose LLM (GPT-4, Claude, Gemini) for actual patch generation. This architecture deliberately decouples context acquisition from patch generation, letting us leverage state-of-the-art LLMs while maintaining precise control over what information they receive.
┌─────────────┐
│ Crash Log │
│ + Metadata │
└──────┬──────┘
│
▼
┌─────────────────────┐
│ Retrieval Policy π │◄─── Custom Model (Llama-3.2-3B)
│ "What should I │
│ retrieve next?" │
└──────┬──────────────┘
│
│ Actions: retrieve ngx_http_userid_ctx_t,
│ retrieve NGX_CUSTOM_FEATURE__NR, ...
▼
┌──────────────────────┐
│ Environment │
│ (Code Context │
│ Builder) │
└──────┬───────────────┘
│
│ Updated context with retrieved symbols
▼
Repeat for H turns
│
▼
┌──────────────────────┐
│ Patch Generation LLM │◄─── GPT-4 / Claude / Gemini
│ (with full context) │
└──────┬───────────────┘
│
▼
Generated Patch
The key insight: smaller specialized models can learn effective retrieval strategies through task-specific training, reducing the need for expensive general-purpose models to do everything.
Multi-Turn GRPO: Learning from Success
We train our retrieval policy using Group Relative Policy Optimization (GRPO), adapted for multi-turn retrieval. The training process involves:
1. Reward Modeling: Two components guide learning:
- Format reward ($R_{\mathrm{fmt}}$): Ensures structurally correct retrieval actions (valid markdown, proper symbol identification)
- Soundness reward ($R_{\mathrm{snd}}$): Assesses whether the final patch compiles, preserves functionality, and fixes the vulnerability
2. Multi-Turn Trajectory Optimization: Unlike standard single-turn GRPO, our agent generates trajectories of retrieval actions over multiple turns. Each turn builds on previous retrievals, gradually constructing the context needed for successful patching.
3. Online Learning: Rather than training on all challenge project vulnerabilities (CPVs) simultaneously—which would be memory-intensive—we update the policy online. The agent concentrates on a single CPV repeatedly until reaching a success plateau, then advances to the next. This mirrors how developers work: deep focus on one problem before moving to the next.
# Simplified training objective (multi-turn GRPO)
for cpv in challenge_project_vulnerabilities:
for turn in range(H): # H retrieval turns
# Generate retrieval actions
actions = policy(context)
# Execute retrieval, update context
context = environment.retrieve(actions)
# Compute rewards (format + soundness)
reward = compute_reward(actions, context)
# Update policy based on reward
policy.update(reward, keep_close_to_reference_policy)
The magic happens in that last line: the policy learns which symbols are worth retrieving by directly optimizing for patch success.
A Real Example: babynginx/cpv-0
Let’s walk through how the learned policy works in practice. We’ll use babynginx/cpv-0, an internal benchmark motivated by CVE-2022-0995 (an out-of-bounds access in the Linux kernel), adapted to a simplified Nginx setting.
The Bug: The vulnerability arises when parsing a custom request header X-Feature. A numeric value gets converted using ngx_atoi and used to set a bitmap index. The range check incorrectly uses sizeof(bitmap) * BITS_PER_LONG, permitting out-of-bounds access.
Turn 1: Fault Localization
The process begins with an AddressSanitizer report indicating the failure site:
==1234==ERROR: AddressSanitizer: heap-buffer-overflow
#0 0x7f8b4c in ngx_http_process_custom_features /nginx/src/http/ngx_http_custom.c:156
#1 0x7f8b2a in ngx_http_process_request /nginx/src/http/ngx_http_request.c:2891
Retrieved Action (with reasoning from the model):
The potential vulnerability is an out-of-bounds read error in the `ngx_http_process_custom_features` function. The crash occurs at line 156 when processing custom features.
**Relevant Symbols:**
1. `ngx_http_process_custom_features`
Without this initial localization, subsequent retrievals would lack direction. The model learns that crash stack traces point to critical functions.
Turn 2: Expanding Context
At this stage, partial context has been assembled, but crucial information about valid feature indices is missing.
// Augmented Code Context
[148]: static void ngx_http_process_custom_features(ngx_http_request_t *r) {
[149]: ngx_int_t feature_id;
[150]: feature_id = ngx_atoi(r->headers_in->x_feature->value.data,
[151]: r->headers_in->x_feature->value.len);
[152]:
[153]: // BUG: incorrect bound check
[154]: if (feature_id >= 0 &&
[155]: feature_id < sizeof(r->http_features->bitmap) * BITS_PER_LONG) {
[156]: ngx_set_bit(r->http_features->bitmap, feature_id); // @BUG_HERE
[157]: }
[158]: }
Retrieved Action:
The following symbols are relevant to the provided C code snippet:
**Relevant Symbols:**
1. `ngx_http_features_t` (structure definition)
2. `NGX_CUSTOM_FEATURE__NR` (boundary constant)
The model has learned that structure definitions and boundary constants are critical for understanding buffer limits.
Before Turn 3: The Critical Discovery
The context builder retrieves the header file, uncovering the missing structure:
// Augmented Code Context
typedef struct {
unsigned long bitmap[2];
} ngx_http_features_t;
#define NGX_CUSTOM_FEATURE__NR 64
This discovery is decisive. The macro NGX_CUSTOM_FEATURE__NR specifies the upper bound of valid feature indices. Our empirical evaluation showed that without retrieving this symbol, LLM-generated patches consistently failed—either uncompilable or logically unsound.
The Generated Patch
With complete context, the patching LLM generates:
--- a/src/http/ngx_http_custom.c
+++ b/src/http/ngx_http_custom.c
@@ -152,7 +152,7 @@ static void ngx_http_process_custom_features(ngx_http_request_t *r) {
r->headers_in->x_feature->value.len);
- if (feature_id >= 0 &&
- feature_id < sizeof(r->http_features->bitmap) * BITS_PER_LONG) {
+ if (feature_id >= 0 && feature_id < NGX_CUSTOM_FEATURE__NR) {
ngx_set_bit(r->http_features->bitmap, feature_id);
}
}
The key improvement: replacing a brittle size-based bound with a semantically correct check against NGX_CUSTOM_FEATURE__NR. This ensures both memory safety and logical correctness.
Training Dynamics: What Actually Happens
We fine-tuned a custom model based on Meta’s Llama-3.2-3B-Instruct on 7 CPV instances, training on 8× NVIDIA A100 (80GB) GPUs. The hyperparameters were optimized for code retrieval:
- Context Window: 8,192 tokens max prompt, 10,240 total sequence length
- Parameter-Efficient Fine-Tuning: LoRA with rank 32 and alpha 32
- Optimization: AdamW with learning rate $5 \times 10^{-6}$
- GRPO Group Size: 12 parallel generations per step
- Retrieval Turns: $H = 4$ steps per episode
- Downstream Evaluation: GPT-4.1 for patch generation
The training trajectories reveal fascinating patterns:
- Early Sparse Successes: In many CPVs, the maximum reward spikes to 1.0 well before the mean reward rises. This confirms the utility of group-based optimization—even when the policy is immature, diversity in rollouts can surface a correct retrieval path.
- Staircase-like Improvement: Mean reward increases in discrete jumps rather than smoothly. This reflects the sequential nature of retrieval: once the policy learns to fetch a critical symbol, downstream steps become substantially easier.
- Project-Dependent Difficulty: Some projects show long flat regions with zero reward, while others exhibit frequent reward spikes. This suggests varying difficulty in context localization across different codebases.
- Persistence Matters: The recurrence of max-reward spikes across epochs indicates that repeated attempts in our online learning don’t merely overfit—they stabilize the policy so success can be rediscovered consistently.
Results: Does It Actually Work?
We evaluated our custom model on 18 CPVs across three checkpoints (rc1, rc2, rc3). Here’s the breakdown:
| Success Rate | Checkpoint 1 | Checkpoint 2 | Checkpoint 3 |
|---|---|---|---|
| Sound Patches | 9/18 (50%) | 11/18 (61%) | 10/18 (56%) |
Key Insights:
- Overall performance: Roughly half of all patch attempts succeeded, demonstrating the agent can generate compilable fixes across diverse bug types
- Checkpoint progression: Later checkpoints showed fewer severe failures, suggesting moderate improvements over initial training
- Consistent failures: Certain CPVs (e.g.,
freerdp-1,freerdp-2,libpng-1) failed across all checkpoints—indicating bug classes that remain difficult - Reliable successes: Other CPVs (e.g.,
integration-test-1/2,libexif-1/2,libxml2-1,sqlite3-5) succeeded consistently, showing sufficient retrieval context for these categories
AIxCC Final Competition: Real-World Performance
The true test came at the DARPA AIxCC Final Competition, where our custom model-powered agent faced real-world vulnerabilities under competitive conditions. Here’s a concrete example of how our approach performed in the high-stakes finals.
Case Study: Wireshark BER Stack Buffer Overflow
The Challenge: A stack-buffer-overflow vulnerability in Wireshark’s BER (Basic Encoding Rules) dissector—specifically in the dissect_ber_GeneralString function. This is exactly the kind of complex, real-world vulnerability that tests whether AI-assisted patching actually works.
The Crash Log: Our agent received this AddressSanitizer report:
==ERROR: AddressSanitizer: stack-buffer-overflow on address 0x7fff501517bd
at pc 0x000005431adb bp 0x7fff50151670 sp 0x7fff50151668
WRITE of size 1 at 0x7fff501517bd thread T0
SCARINESS: 46 (1-byte-write-stack-buffer-overflow)
#0 0x5431ada in dissect_ber_GeneralString /src/wireshark/epan/dissectors/packet-ber.c:3194:34
#1 0x542899b in try_dissect_unknown_ber /src/wireshark/epan/dissectors/packet-ber.c:935:26
#2 0x5b84ecd in call_dissector_through_handle /src/wireshark/epan/packet.c:887:9
...
Address 0x7fff501517bd is located in stack of thread T0 at offset 93 in frame
#0 0x5427a1f in try_dissect_unknown_ber /src/wireshark/epan/dissectors/packet-ber.c:814
This frame has 12 object(s):
[32, 40) 'val.i510' (line 2021)
[64, 72) 'val.i' (line 2021)
[96, 97) 'ber_class' (line 816) <== Memory access at offset 93 underflows this variable
...
The Complexity: This bug involves:
- Stack memory layout with precise bounds
- Multiple function calls through dissector handlers
- Buffer size management across different code paths
- Complex interaction between
name_string,max_len, and actual buffer capacity
The Generated Patch: Our custom model-powered agent successfully identified the vulnerable code and generated this sound patch:
diff --git a/epan/dissectors/packet-ber.c b/epan/dissectors/packet-ber.c
index ce97968..42ba5c2 100644
--- a/epan/dissectors/packet-ber.c
+++ b/epan/dissectors/packet-ber.c
@@ -3054,8 +3054,8 @@ dissect_ber_GeneralString(asn1_ctx_t *actx, proto_tree *tree, tvbuff_t *tvb, int
proto_item *cause;
str = str_arr;
- max_len = 255;
- if (name_string) {
+ max_len = sizeof(str_arr);
+ if (name_string && name_len > 0) {
str = name_string;
max_len = name_len;
}
@@ -3086,12 +3086,17 @@ dissect_ber_GeneralString(asn1_ctx_t *actx, proto_tree *tree, tvbuff_t *tvb, int
return end_offset;
}
+ /* Ensure we do not write out of bounds; always leave space for NUL. */
if (len >= (max_len - 1)) {
- len = max_len - 1;
+ len = max_len > 0 ? max_len - 1 : 0;
+ }
+ /* If buffer for output is 0, skip copy */
+ if (max_len > 0 && len > 0) {
+ tvb_memcpy(tvb, str, offset, len);
+ str[len] = 0;
+ } else if (max_len > 0) {
+ str[0] = 0;
}
-
- tvb_memcpy(tvb, str, offset, len);
- str[len]=0;
if (hf_id > 0) {
proto_tree_add_string(tree, hf_id, tvb, offset, len, str);
@@ -3178,7 +3183,7 @@ dissect_ber_GeneralString(asn1_ctx_t *actx, proto_tree *tree, tvbuff_t *tvb, int
offset = dissect_ber_restricted_string(false, BER_UNI_TAG_GeneralString, actx, tree, tvb, offset, hf_id, (name_string) ? &out_tvb : NULL);
- if (name_string) {
+ if (name_string && name_len > 0) {
/*
* XXX - do we want to just get what's left in the tvbuff
* if the full length isn't available in the tvbuff, or
@@ -3186,12 +3191,12 @@ dissect_ber_GeneralString(asn1_ctx_t *actx, proto_tree *tree, tvbuff_t *tvb, int
*/
if (out_tvb) {
tvb_len = tvb_get_uint8(tvb, offset);
- if ((unsigned)tvb_len >= name_len) {
- tvb_memcpy(out_tvb, (uint8_t*)name_string, 0, name_len-1);
- } else {
- tvb_memcpy(out_tvb, (uint8_t*)name_string, 0, tvb_len);
+ /* Clamp copy len to fit inside output buffer */
+ unsigned copy_len = ((unsigned)tvb_len < (name_len - 1)) ? (unsigned)tvb_len : (name_len - 1);
+ if (copy_len > 0) {
+ tvb_memcpy(out_tvb, (uint8_t*)name_string, 0, copy_len);
}
- name_string[tvb_len] = '\0';
+ name_string[copy_len] = '\0';
}
}
Why This Patch is Sound
The generated patch demonstrates sophisticated understanding of the vulnerability:
- Correct Buffer Size Calculation: Changed from hardcoded
max_len = 255tomax_len = sizeof(str_arr), ensuring the size matches actual buffer allocation. - Defensive Null Checks: Added
name_len > 0validation in multiple places to prevent zero-length buffer operations that could cause underflows. - Safe Length Clamping: Implemented proper bounds checking with
len = max_len > 0 ? max_len - 1 : 0to handle edge cases wheremax_lenmight be zero. - Conditional Memory Operations: Wrapped
tvb_memcpycalls in guards checking bothmax_len > 0andlen > 0, preventing out-of-bounds writes entirely. - Improved Copy Length Logic: In the second location, replaced conditional logic with a single clamped
copy_lencalculation, making the bounds checking explicit and auditable.
What This Demonstrates
This real-world example validates several key aspects of our approach:
- Context Learning in Action: The model successfully retrieved and utilized context about buffer structures, size constraints, and calling patterns to generate a comprehensive fix addressing multiple vulnerable code paths.
- Security-Aware Patching: The patch doesn’t just stop the crash—it implements defense-in-depth by adding multiple layers of validation, showing the model learned security principles beyond simple syntax fixes.
- Production-Ready Quality: The generated code includes appropriate comments, maintains code style consistency, and handles edge cases that human reviewers would expect in a professional security patch.
- Competition Performance: This success in the high-pressure AIxCC Finals environment demonstrates that learned retrieval policies can generalize to unseen vulnerabilities in real-world, large-scale codebases like Wireshark.
Key Findings and Contributions
After developing and evaluating custom models for patching, here’s what we learned:
- ✅ With proper code context, commercial LLMs generate secure patches: When provided comprehensive and relevant code context through multi-turn retrieval, state-of-the-art commercial models demonstrate strong capability in producing functionally correct and security-compliant patches.
- ✅ Pretrained models have fair baseline performance: Base models like Llama-3.2-3B-Instruct exhibit reasonable baseline performance in identifying relevant code artifacts, providing a solid foundation for specialization.
- ✅ RL fine-tuning improves context selection: Reinforcement learning using multi-turn GRPO significantly enhances the model’s ability to select optimal code contexts, leading to measurable improvements in patch generation quality.
- ⚠️ Forgetting remains a challenge: Online learning introduces catastrophic forgetting—knowledge from earlier CPVs degrades when adapting to new instances, limiting overall training effectiveness.
Contributions to the Field
This work makes several key contributions to AI-assisted security patch generation:
- Empirical Validation of Context Importance: We demonstrate that providing missing code context (e.g., undefined symbol definitions) is crucial for sound patch generation by LLMs—a 5/20 → 18/20 success rate improvement.
- Multi-Turn Retrieval Framework: We propose and train a novel multi-turn retrieval agent that iteratively retrieves concise, targeted code context, enabling effective utilization of powerful yet context-limited commercial LLMs.
- Effectiveness on Real-World Benchmarks: We demonstrate the efficacy of learned multi-turn retrieval through successful participation in the DARPA AIxCC competition, where context quality directly impacted patch success rates.
Limitations and Future Directions
Our approach has several practical limitations worth acknowledging:
- Language Scope: Current implementation specializes for C codebases and hasn’t been extended to other languages like Java or Python.
- Restricted Retrieval Scope: The retrieval process focuses only on function definitions, method definitions, and type definitions—potentially overlooking other useful artifacts like build scripts or configuration files.
- Tooling Overhead: Our use of parser-based tools required manual adapter development, limiting scalability. Broader, language-agnostic tools would improve generality.
- Catastrophic Forgetting: The online learning approach can degrade retrieval policies learned on earlier CPVs when adapting to new ones—a classic RL challenge.
- Competition Constraints: Late rule changes in the competition limited available custom model learning time and validation breadth.
Future Research Opportunities
The most exciting opportunities ahead:
- Expanding Language Support: Adapting the retrieval framework to Java, Python, Rust, and other languages with appropriate parsers and symbol extraction tools.
- Richer Retrieval Actions: Beyond function and type definitions, retrieving documentation, test cases, commit history, and related patches could provide valuable context.
- Addressing Catastrophic Forgetting: Techniques like experience replay, progressive neural networks, or meta-learning could help retain knowledge across CPVs while adapting to new ones.
- Integrating with RAG Systems: Combining learned retrieval policies with retrieval-augmented generation could dynamically pull in relevant vulnerability patterns and exploitation knowledge.
- Human-in-the-Loop Refinement: Interactive systems where security experts guide retrieval strategies could accelerate learning and improve policy quality.
What This Means for Security
Code context learning represents a fundamental shift from manual prompt engineering to adaptive, learnable approaches in AI-assisted security.
Instead of hand-crafting heuristics for what context matters, we’re training specialized models to discover these patterns through reinforcement learning. The result? Systems that adapt to different bug types, codebases, and patching scenarios without constant human intervention.
This isn’t just about patching faster—it’s about patching smarter. As vulnerabilities grow more complex and codebases more massive, the ability to automatically identify and retrieve relevant context becomes critical for scalable automated security.
The future of security patching isn’t about replacing human expertise—it’s about teaching AI to learn what context matters, amplifying human judgment at machine scale. Custom models for code context learning represent one step toward that future.

