
ClaudeLike: How to Apply a Tool-Based Agent to Patch Generation
- Hyeon Heo
- Atlantis patch
- October 10, 2025
Table of Contents
Claude Code is an LLM agent specialized in general-purpose programming tasks and remains one of the most powerful LLM agents to date. Inspired by Claude Code’s strategy, we developed ClaudeLike, an agent dedicated to patch generation. In this post, we introduce the motivation and key features behind the development of ClaudeLike.
Motivation: Applying a SOTA LLM Agent to Patch Generation
Why Did We Need to Develop a New Agent?
When Claude Code was released, we experimented to see whether it could generate patches effectively, as we had previously done with tools like Aider and SWE-Agent. We found that Claude Code performed reasonably well when provided with contextual information such as crash logs. However, we determined that directly integrating Claude Code into Crete would be difficult.
The main reason is that Claude Code’s internals cannot be modified, which would limit our ability to add or customize tools in the future. Additionally, some of Claude Code’s built-in tools—such as Bash or WebFetchTool—were unnecessary for our use case and could lead to unpredictable behavior.
Core Strategy
Instead of integrating Claude Code directly into Crete, we decided to build a new agent that adopts its core strategies. Through an in-depth analysis of Claude Code, we found that two design aspects have a significant impact on its performance:
- A well-designed file editor tools that enables efficient analysis and modification of project structures and files.
- The use of a sub-agent to perform smaller, multi-step tasks, thereby reducing the context burden on the main agent.
With these two strategies as the foundation, we developed ClaudeLike.
Implementation: File Editor Tools and AgentTool
ClaudeLike generates patches through the following three steps:
- It constructs a prompt from the PoC and SARIF report, then passes it to the ClaudeLike coder.
- The ClaudeLike coder locates and fixes the buggy code within the project, producing a patch diff.
- The agent evaluates whether the generated patch diff is sound. If not, it provides feedback to the coder to regenerate a new patch.
The overall structure is similar to that of other simple patch-generating agents. The coder plays the role analogous to Claude Code, and its structure is as follows:
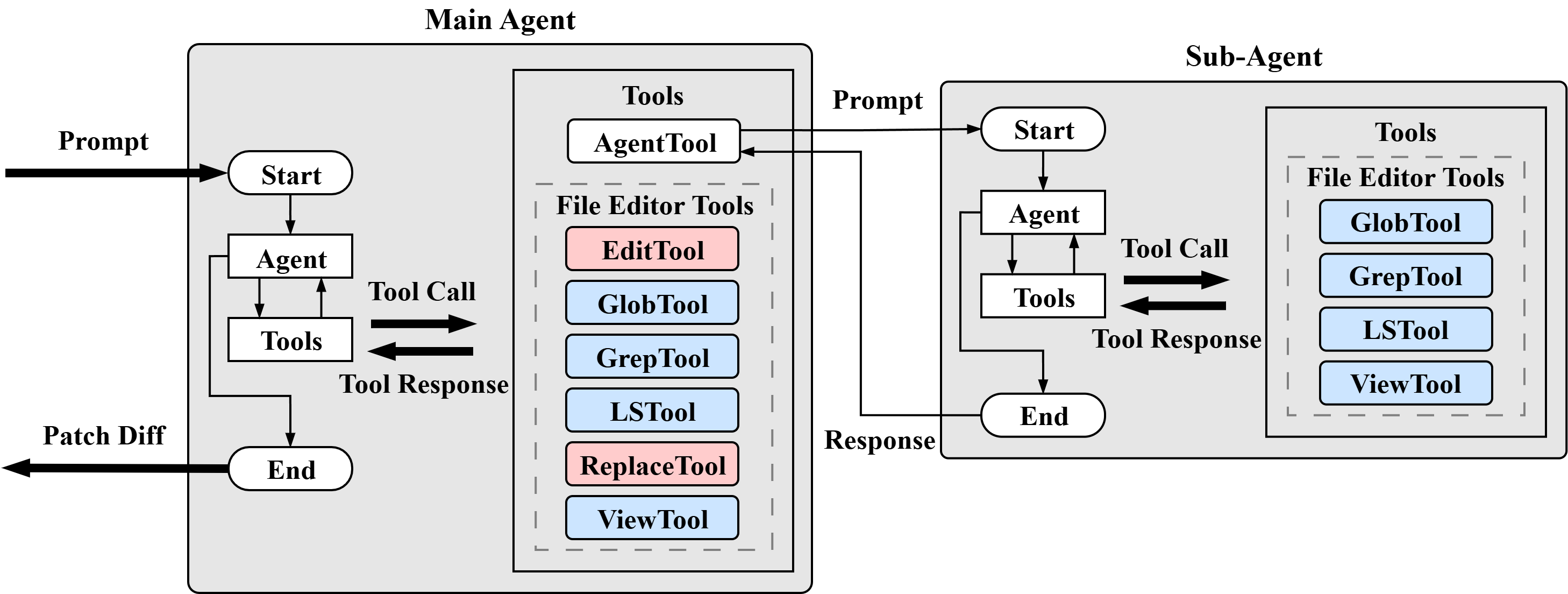
Fig.1 High-level overview of Martian Agent
The ClaudeLike coder’s main agent is composed of file editor tools and an AgentTool. The main agent interacts with the project by invoking file editor tools and can also spawn a sub-agent to perform specific tasks.
File Editor Tools: Enabling Agent–Project Interaction
ClaudeLike analyzes and modifies projects using six file editor tools inspired by Claude Code:
- EditTool(file_path, old_string, new_string): Replaces the old_string from the file in file_path into new_string. The old_string must exist in the file and be uniquely matched in the file.
- GlobTool(pattern, path): Returns the list of files in the path directory whose filenames match the glob pattern.
- GrepTool(pattern, path, include): Returns the list of files in the path directory whose content match the given regex expression pattern. The result only includes files whose filenames match the glob pattern include.
- LSTool(path): Returns the list of files in the path directory.
- ReplaceTool(file_path, content): Replaces the content of file file_path into given content. If the file file_path does not exist, ReplaceTool creates it and sets the content of the file as content.
- ViewTool(file_path, offset, limit): Returns the maximum limit lines of the file file_path starts from line number offset
Each tool’s description explicitly defines when it should be used, its constraints, and the valid argument types. By referencing these descriptions, the agent can select and use the appropriate tools to accomplish its tasks effectively.
AgentTool: Helping the Agent Stay Focused
In the libxml2 project from Round 3, a double-free vulnerability was discovered. The following is a portion of the ASAN crash log output when this vulnerability is triggered:
==ERROR: AddressSanitizer: attempting double-free on 0x5020000008b0 in thread T0:
SCARINESS: 42 (double-free)
#0 0x563555fc1f66 in free /src/llvm-project/compiler-rt/lib/asan/asan_malloc_linux.cpp:52:3
#1 0x5635560b54b4 in xmlParseAttribute2 /src/libxml2/parser.c:9028:13
#2 0x5635560ad714 in xmlParseStartTag2 /src/libxml2/parser.c:9233:13
#3 0x56355607b6d0 in xmlParseElementStart /src/libxml2/parser.c:10136:16
#4 0x56355607a997 in xmlParseElement /src/libxml2/parser.c:10071:9
#5 0x5635560864f1 in xmlParseDocument /src/libxml2/parser.c:10902:2
#6 0x56355609bb88 in xmlCtxtParseDocument /src/libxml2/parser.c:13988:5
#7 0x56355609f024 in xmlCtxtReadMemory /src/libxml2/parser.c:14314:12
#8 0x563556001bd4 in LLVMFuzzerTestOneInput /src/libxml2/fuzz/xml.c:68:15
#9 0x563555eb6430 in fuzzer::Fuzzer::ExecuteCallback(unsigned char const*, unsigned long) /src/llvm-project/compiler-rt/lib/fuzzer/FuzzerLoop.cpp:614:13
#10 0x563555ea16a5 in fuzzer::RunOneTest(fuzzer::Fuzzer*, char const*, unsigned long) /src/llvm-project/compiler-rt/lib/fuzzer/FuzzerDriver.cpp:327:6
#11 0x563555ea713f in fuzzer::FuzzerDriver(int*, char***, int (*)(unsigned char const*, unsigned long)) /src/llvm-project/compiler-rt/lib/fuzzer/FuzzerDriver.cpp:862:9
#12 0x563555ed23e2 in main /src/llvm-project/compiler-rt/lib/fuzzer/FuzzerMain.cpp:20:10
#13 0x7fec0f842082 in __libc_start_main (/lib/x86_64-linux-gnu/libc.so.6+0x24082) (BuildId: 5792732f783158c66fb4f3756458ca24e46e827d)
#14 0x563555e9988d in _start (/out/xml+0x18388d)
DEDUP_TOKEN: __interceptor_free--xmlParseAttribute2--xmlParseStartTag2
0x5020000008b0 is located 0 bytes inside of 9-byte region [0x5020000008b0,0x5020000008b9)
freed by thread T0 here:
#0 0x563555fc1f66 in free /src/llvm-project/compiler-rt/lib/asan/asan_malloc_linux.cpp:52:3
#1 0x5635560b541f in xmlParseAttribute2 /src/libxml2/parser.c:9024:17
#2 0x5635560ad714 in xmlParseStartTag2 /src/libxml2/parser.c:9233:13
...
To patch this vulnerability, the agent must first identify its root cause.
For this purpose, the agent examines the point where the double free occurs—specifically, the implementation of the xmlParseAttribute2 function in libxml2/parser.c.
Benchmark results show that the process of locating and reviewing this function’s implementation involves a series of file editor tool calls as follows.
(The xmlParseAttribute2 function is implemented between line 8823 and line 8927 in parser.c.)
- Use
GlobToolto search for the file matching the pattern**/parser.cto locate its exact path. - Use
ViewToolto read 100 lines starting from line 9000 ofparser.c. - Use
GrepToolto check whether the stringxmlParseAttribute2exists inparser.c. - Use
ViewToolagain to view 100 lines from line 8800. - Use
ViewToolonce more to view 200 lines starting from line 8900.
As seen above, even to inspect the contents of a single suspected function, the agent needs to make five separate file editor tool calls. If the target function is not located where expected or spans more lines than anticipated, the number of tool calls required will increase. In fact, the Apache Commons Compress project in the Round 2, identifying the file containing a specific method required 23 file editor tool calls in total.
Tasks such as examining function implementations or reviewing files are essential for patch generation and may occur multiple times during the patch process. However, each tool call adds to the agent’s context length. As a result, the agent may lose focus on its primary task—patch generation. Furthermore, since the agent retains the parameters and results of all previous tool calls in its context, a large number of tool invocations significantly increases the number of input tokens per completion. This, in turn, leads to frequent issues such as rate limit exceedances or context window size exceedances.
To address this, ClaudeLike adopts AgentTool, similar to Claude Code. The main agent can invoke the AgentTool to delegate specific tasks to a sub-agent. Sub-agent operates independently of the main agent, makes its own tool calls, and returns results to the main agent. This design allows the main agent to offload repetitive or verbose tasks (e.g., identifying file functionality or searching for files), thus keeping its context concise and focused on generating patches.
To prevent uncontrolled recursion, a sub-agent is not allowed to use AgentTool itself. Additionally, to avoid unintended code modifications, a sub-agent is restricted from using EditTool and ReplaceTool.
Ensuring Robustness under Unstable LLM Server Conditions
Tool calls are executed through model invocations. In other words, if a model invocation fails, the corresponding tool call cannot be made, which in turn results in the failure of the entire agent system.
Throughout the Rounds, we observed that both the LiteLLM server and Claude API were not always stable. Since not only the patch system but also other components of the overall Atlantis system send LLM requests, issues such as limited TPM or system overload occasionally prevented LLM model invocations from completing successfully.
To address these issues, ClaudeLike repeatedly performs model invocations until they succeed. Furthermore, to prevent its LLM requests from causing congestion across the entire system, ClaudeLike implements exponential backoff as a form of congestion control.
Differences from Claude Code
While the core idea of ClaudeLike originates from Claude Code, there are several key differences between the two.
The most significant distinction lies in the tool configuration. ClaudeLike excludes tools that are unrelated to patch generation or may cause side effects—for instance, tools designed for Jupyter notebooks such as ReadNotebook and NotebookEditCell, tools that require an online environment such as WebFetchTool, and command-execution tools like Bash.
In addition, as mentioned in the previous section, ClaudeLike carefully handles exceptions that may occur during API calls or tool invocations to prevent system-wide failures. Furthermore, to reduce common mistakes made by the agent during patch generation, we added a set of explicit instructions to the system prompt.
Limitations
ClaudeLike demonstrated quite strong performance in the benchmarks conducted during its development. However, there are several areas where further improvement is needed.
Our initial goal in developing ClaudeLike was to explore how applying custom tools (e.g., gdb interface), expected to be effective for patching, on a SOTA agent like Claude Code, would impact performance. Due to limited development and stabilization time, this goal could not be fully realized.
Another limitation is that certain tools from Claude Code, which were anticipated to be useful for patch generation—such as Bash and BatchTool—were excluded. Bash was omitted from ClaudeLike due to potential side effects, although with proper sandboxing, it could have been quite valuable. BatchTool, which allows multiple tools in Claude Code to be executed simultaneously, was also deprioritized and ultimately not incorporated into ClaudeLike. Its inclusion could have helped reduce context length and improve the efficiency of tool calls.
Conclusion
In this post, we discussed ClaudeLike, an agent inspired by Claude Code’s design principles. Evaluation results show that ClaudeLike successfully generates sound patches for most cases in the Round 3 dataset. Furthermore, through repeated benchmarking, we observed that performance varied significantly depending on the clarity and specificity of tool descriptions and whether AgentTool was enabled.
These findings suggest that strategies used in general-purpose software engineering agents can also be effectively applied to security patch generation. In particular, providing well-defined tools with precise instructions and enabling the agent to maintain focus by reducing context size are proven to be effective strategies for tool-based agents performing patch generation.


