
Atlantis Infrastructure
- HyungSeok Han
- Atlantis
- August 13, 2025
Table of Contents
The AIxCC competition is not just about creating automated bug-finding and patching techniques – it is about building a cyber reasoning system (CRS) that can do both without any human assistance. To succeed, a CRS must excel in four critical infrastructure areas:
- Reliability: Run continuously for weeks without intervention.
- Scalability: Handle many challenge projects concurrently.
- Budget Utilization: Maximize Azure cloud and LLM credit usage.
- Submission Management: Consistently deliver valid proof-of-vulnerability blobs (POVs), Patches, SARIF assessments, and Bundles.
In this post, we will share how we designed the infrastructure of our CRS, Atlantis, to meet these keys and make it as robust as possible. We could not have won AIxCC without the exceptional work of our infrastructure team.
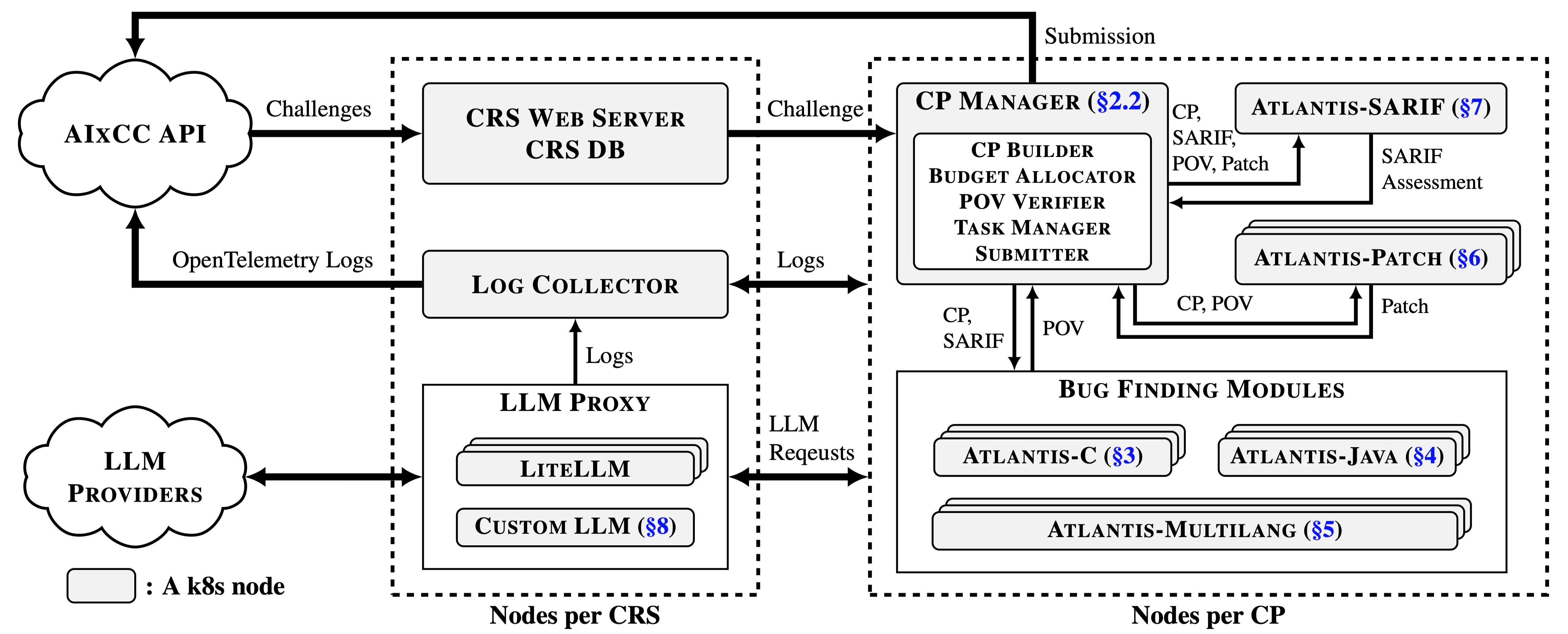
1. Bootstrapping
Atlantis starts by launching CRS-level k8s nodes for four essential services:
- CRS Webserver: Listens for incoming challenge projects (CPs) and SARIF reports.
- Log Collector: Aggregates and forwards logs to the AIxCC organizers.
- LiteLLM: Manages LLM usage within budget and logs all requests/responses.
- Custom LLM: Helps patch generation based on fine-tuned LLM.
2. Per-Challenge Scaling
When a new CP arrives, the CRS webserver spins up a dedicated CP manager on its own k8s node. The CP manager then:
Builds the CP and allocates both Azure Cloud and LLM budgets proportionally for this CP.
Launches bug-finding modules depending on the language:
- C-based CPs => Atlantis-Multilang + Atlantis-C
- Java-based CPs => Atlantis-Multilang + Atlantis-Java
Launches Atlantis-Patch and Atlantis-SARIF for patch generation and SARIF assessment.
Issues LiteLLM API keys to modules to enforce per-CP and per-module LLM budgets.
This per-challenge scaling significantly boosts reliability – if crash while handling one CP, it does not affect others. Redundant bug-finding modules further improve stability and coverage; for example, if Atlantis-C fails on certain CPs, Atlantis-Multilang can still find vulnerabilities in them.
Here are the statistics on POVs from the final competition.
+--------------------+--------------------------+
| Module | POV Submission by Module |
+--------------------+--------------------------+
| Atlantis-Multilang | 69.2% |
| Atlantis-C | 16.8% |
| Atlantis-Java | 14.0% |
+--------------------+--------------------------+
+-------------+---------------------------------+
| CP Language | POV Distribution by CP Language |
+-------------+---------------------------------+
| C-based | 78.5% |
| Java-based | 21.5% |
+-------------+---------------------------------+
In addition, for each harness in a CP, Atlantis-Multilang and Atlantis-Java run on nodes sized according to the allocated Azure budget, while Atlantis-C operates on a fixed pool of up to 15 nodes. This isolation ensures that even if a module fails on one harness, it does not impact the others.
This per-challenge scaling also enabled us to make full use of the allocated Azure Cloud and LLM credit budgets. In the final round, as shown below, we recorded the highest usage among all seven teams – spending $73.9K of the $85K Azure Cloud budget and $29.4K of the $50K LLM credit budget.
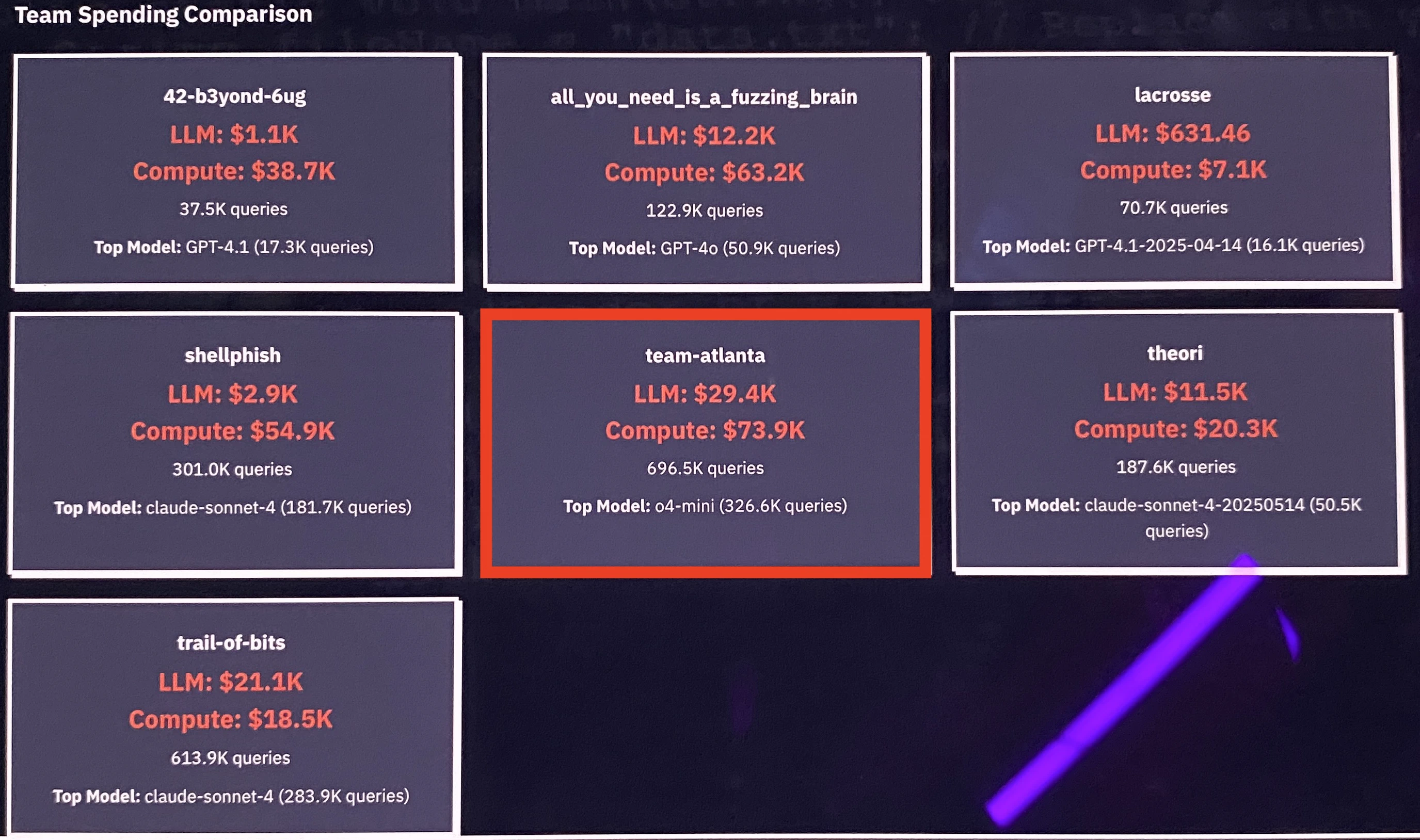
Notably, the above image and the AIxCC organizers show that we primarily used o4-mini, GPT-4o, and o3. However, these are based on the number of requests rather than the actual LLM credits spent in dollars. Based on our experience from the practice and internal rounds, we allocated LLM budgets in the final round as shown below. While our plan was to rely mostly on Anthropic and OpenAI models in the final round, we do not yet have precise data on how much we spent for each provider.
+--------------------+-----------+------------+----------+--------+-----------+
| CRS | OpenAI | Anthropic | Gemini | Grok | Total |
+--------------------+-----------+------------+----------+--------+-----------+
| Atlantis-multilang | 0.48 | 0.48 | 0.05 | 0.00 | 1.00 |
| Atlantis-C/java | 0.40 | 0.30 | 0.30 | 0.00 | 1.00 |
| Atlantis-patch | 0.30 | 0.60 | 0.10 | 0.00 | 1.00 |
+--------------------+-----------+------------+----------+--------+-----------+
| Atlantis-multilang | $8839.29 | $8839.29 | $883.93 | $0.00 | $18562.50 |
| Atlantis-C/java | $7425.00 | $5568.76 | $5568.76 | $0.00 | $18562.50 |
| Atlantis-patch | $3712.50 | $7425.00 | $1237.50 | $0.00 | $12375.00 |
| Atlantis-sarif | $75.00 | $100.00 | $250.00 | $75.00 | $500.00 |
+--------------------+-----------+------------+----------+--------+-----------+
| Total | $20051.79 | $21933.04 | $7940.18 | $75.00 | $50000.00 |
+--------------------+-----------+------------+----------+--------+-----------+
3. Submission and Task Management
When a bug-finding module discovers a POV, it sends the result to the CP Manager. The CP Manager then:
- Verifies that the POV indeed triggers a crash.
- Deduplicates POVs based on their stack traces and heuristics.
- Submit unique POVs to the AIxCC organiziers.
- Forwards unique POVs to Atlantis-Patch and Atlantis-SARIF for patch generation and SARIF assessment.
Once patches and SARIF reports are produced, they are returned to the CP Manager and CP Manager submits them to the AIxCC organizers. At the end, the CP Manager groups each POV with its corresponding patch and assessment (based on the POV hash) into a bundle and submits it to the AIxCC organizers.
As a result, we were able to successfully submit numerous POVs, patches, SARIF assessments, and bundles with high accuracy in the final round and ultimately won the competition, as shown below. Notably, our bundle score was significantly higher than other teams, even when accounting for the large number of POVs we found and patches we generated. This demonstrates that Atlantis was able to effectively map the relationships between discovered POVs, generated patches, and SARIF assessments – a capability that can be incredibly valuable for real-world developers.
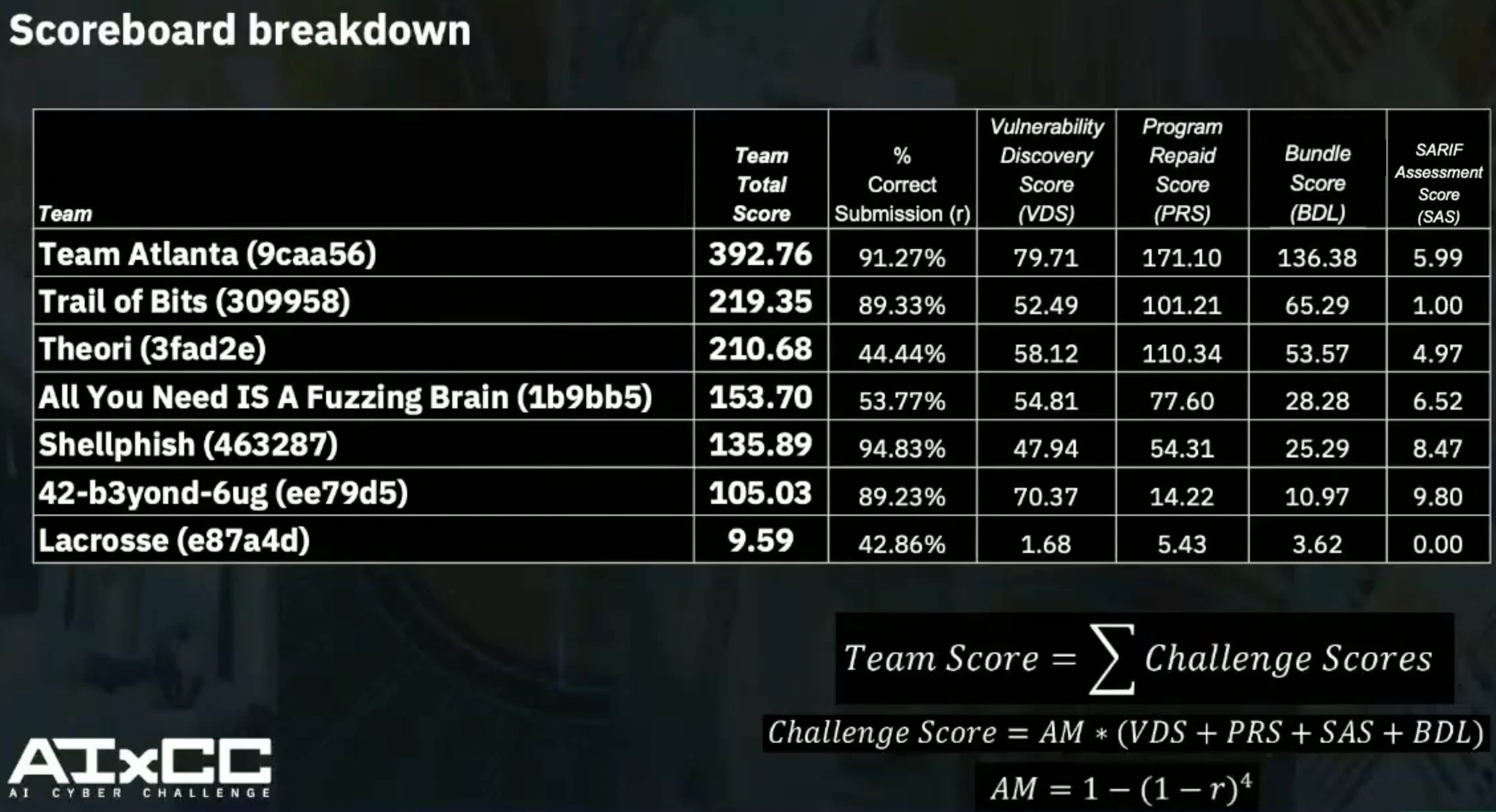
Here is a breakdown of our submission, reconstructed from the logs we were able to recover. Please note that this is not fully accurate since a portion of the logs is missing, and we are not yet certain which submission was ultimately scored. We will provide an updated and verified version once the AIxCC organizers release the official detailed logs.
+--------------------+-------+--------+--------+--------+
| Category | Count | Passed | Failed | Scored |
+--------------------+-------+--------+--------+--------+
| POV -> CP Manager | 1,002 | N/A | N/A | N/A |
| POV -> Organizers* | 107 | 107 | 0 | 43 |
| Patches | 47 | 41 | 6 | 31 |
| SARIF Reports | 8 | N/A | N/A | N/A |
| Bundles | 42 | N/A | N/A | N/A |
+--------------------+-------+--------+--------+--------+
*: after POV verification & deduplication
`Scored`: Marked after the AIxCC organizers manually reviewed `Passed` result
Testing, Testing, and Testing!
While developing Atlantis, we conducted extensive testing to fix bugs and evaluate the effectiveness of each module. Under the leadership of Jiho Kim, we prepared over 50 CP benchmarks and tested Atlantis against them using a test version of AIxCC competition server. This allowed us to perform end-to-end testing not only in the three practice rounds provided by the AIxCC organizers, but also in four additional internal rounds. Across these seven rounds, we identified and fixed numerous bugs, ultimately making Atlantis far more robust. Notably, some modules like Atlantis-Multilang has their own CIs to test and evaluate themselves based on our benchmarks. We plan to release our benchmarks once we determine a way to prevent GenAI models from training on them.
Fixed a fatal bug right before the deadline
However, even with extensive testing, we failed to catch a fatal bug in Atlantis-Patch, described in our previous post, until the final moments before submission.
The bug was related to enforcing a rule that Atlantis-Patch must not modify the given fuzzing harnesses.
Our implementation treated any file whose path contained fuzz as a fuzzing harness and blocked modifications accordingly.
Everything worked fine in our internal tests.
But, during the final testing with the AIxCC organizers’ API right before submission, we discovered that all CPs had their directories prefixed with ossfuzz.
As a result, Atlantis-Patch refused to generate any patches.
Initially, I suspected the issue was due to the non-deterministic nature of LLMs.
However, Soyeon spotted unusual log entries with Permission denied, revealing that the patch process was blocked because it attempted to modify a fuzzing harness.
This was discovered just a few hours before the final submission.
I urgently called our Atlantis-Patch teammates in South Korea at 3 AM their time.
Fortunately, we fixed the issue within an hour and managed to submit Atlantis before the deadline.
From the Author After the Last Commit
Since no human intervention was allowed during the competition, we spent a significant amount of time on infrastructure development and testing. All of infrastructure team members not only worked on their assigned roles (e.g., bug finding, SARIF assessment) but also contributed to infra development and testing on the side. I am deeply grateful to them, and this experience really helped me understand why companies have dedicated DevOps teams. In particular, I have a feeling that as LLMs and GenAI become more widely adopted, specialized LLM DevOps teams will also emerge. I will never forget the times when our LiteLLM had to be rebooted frequently because it could not keep up with requests from our modules. Overall, it was an incredible experience to go beyond a research prototype and operate such a large-scale system in a real competition while collaborating and communicating closely with all the sub-teams (Atlantis-C/Java/Multilang/SARIF/Patch) throughout the journey.


