
AIxCC Final and Team Atlanta
- Taesoo Kim
- Milestone
- August 12, 2025
Table of Contents
Two years after its first announcement at DEF CON 31, our team stood on stage as the winners of the AIxCC Final—a moment we had been working toward since the competition began.
Yet when we heard we placed 1st, relief overshadowed excitement. Why? While competing head-to-head with world-class teams like Theori was a privilege, the real-time, long-running nature of this competition demanded extreme engineering reliability alongside novel approaches to succeed.
Balancing innovation with stability under time pressure proved our greatest challenge. We simply hoped our Cyber Reasoning System (CRS) would run as intended— but it exceeded expectations, outperforming other teams in most categories by significant margins.
In this post, I’ll answer the most common questions we received from the DEF CON audience and share the story behind our victory.

Why were we so anxious? In this competition, a single bug can be fatal. One line of code nearly destroyed our chances.
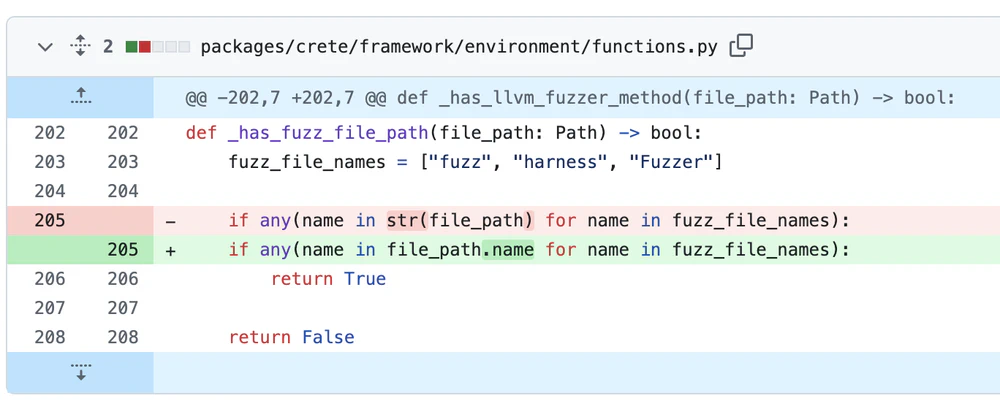
We discovered this critical bug, which almost ended everything, during integration testing— just hours after submitting our final version, and mere hours before the deadline. The problematic code was designed to skip patch generation for fuzzing harnesses. In all previous challenge projects and our benchmarks, fuzzing harness source files contained “fuzz” in their paths (e.g., “fuzz/” or “http_request_fuzzer.cc” in nginx)— a simple but effective heuristic to avoid false positives.
The problem? During our final integration test, we discovered the organizers had prefixed all OSS-Fuzz projects with “ossfuzz” (e.g., “r3-ossfuzz-sqlite3”). The irony wasn’t lost on us—here we were, building an autonomous CRS powered by state-of-the-art AI, nearly defeated by a string matching bug. In postmortem, we figured none of the CP is named with the “fuzz” prefix though!
L0. System Robustness is Priority #1
As our near-miss demonstrated, a single bug can kill a CRS entirely. The autonomous system is that brittle. So how did we balance engineering for robustness with novel research needed to win?
Our answer: N-version programming with orthogonal approaches.
Atlantis isn’t a single CRS—it’s a group of multiple independent CRSs, each designed by specialized teams (C, Java, Multilang, Patch, and SARIF). These teams deliberately pursued orthogonal strategies to maximize both coverage and fault tolerance.
For bug finding alone, we deployed three distinct CRSs:
- Atlantis-Multilang: Built for robustness and language-agnostic bug finding
- Atlantis-C: Optimized specifically for C/C++ vulnerabilities
- Atlantis-Java: Tailored for Java-specific bug patterns
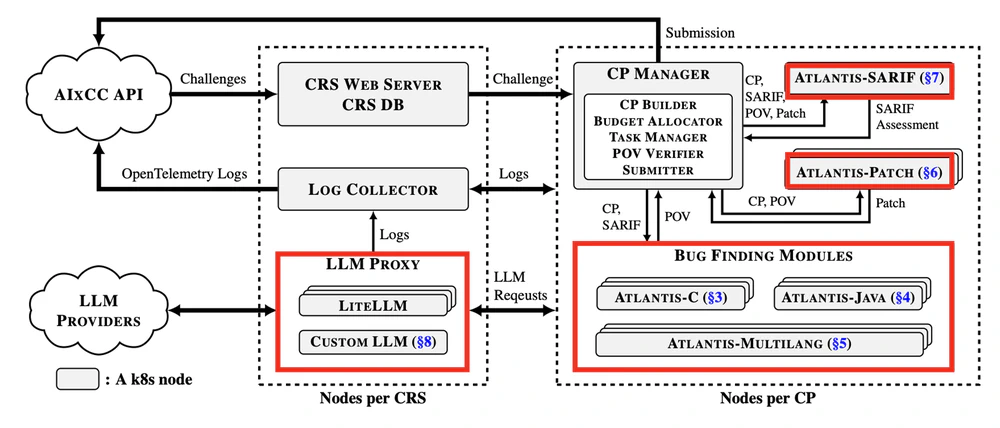
These CRSs deliberately made orthogonal approaches; Atlantis-Multilang took conservative paths (no instrumentation at build time) while Atlantis-C took risky approaches requiring heavy compilation-time instrumentation:
- Atlantis-C CRS:
- ↑ instrumentation: libafl-based, instrument-based directed fuzzer
- ↓ LLM usage: seed generation, input mutation
- Time-based resource allocation
- Atlantis-Multilang CRS:
- ↓ instrumentation: libfuzzer-based, simple seed-based directed fuzzer
- ↑ LLM: seed/blob generation, input format reverser, callgraph, dictgen, etc
- Space-based resource allocation
By maintaining minimal sharing between CRSs and intentionally making orthogonal design decisions, we ensured that a failure in one component wouldn’t cascade through the entire system. When one approach failed, others continued operating— true fault tolerance through diversity.
L1. Don’t Give Up on Traditional Program Analysis
Unlike DARPA’s Cyber Grand Challenge, where CRSs dealt with an artificial architecture limited to 7 system calls, AIxCC evaluates CRSs against real-world, complex open source software— the foundation of today’s cyber infrastructure.
This shift changes everything. Traditional program analysis tools that can’t scale to handle real-world complexity would doom any CRS.
We initially hoped to stand on the shoulders of giants, evaluating most commodity solutions to save development time. Unfortunately, even state-of-the-art tools like SWAT and SymCC weren’t ready for large-scale software analysis. Each required substantial engineering to become competition-ready.
Ultimately, we invested heavily in extending traditional tools. For both C and Java, we developed three categories:
- Ensemble fuzzers: LibAFL for Java/C, libFuzzer, AFL++, custom Jazzer, custom format fuzzers
- Concolic executors: Extended SymCC for C, custom implementation for Java
- Directed fuzzers: Custom implementations for C and Java
Each tool required non-trivial engineering efforts to be effective. The lesson: AI alone isn’t enough—traditional program analysis remains essential, but it must be extensively adapted for real-world scale.
L2. Ensembling to Promote Diversity
Research shows that ensemble fuzzing outperforms single campaigns with equivalent computing resources, as demonstrated by autofz. Atlantis embraces this principle everywhere: coverage-guided fuzzers, directed fuzzers, concolic executors, and patching agents.
Patching particularly benefits from LLM diversity— what the ML community calls “hallucination,” systems engineers call “non-determinism,” and we call “creativity.” By ensembling multiple agents with orthogonal approaches, Atlantis harnesses this non-deterministic nature of LLMs.
The Critical Role of Oracles. Ensembling only works when oracles exist to judge correctness.
In fuzzing, hardware provides our first oracle: segmentation faults from invalid memory access are caught efficiently through page table violations. Software sanitizers extend this scope— ASAN for memory unsafety bugs, UBSAN for undefined behavior, MSAN for memory leaks— detecting bugs long before crashes occur.
For patching, the Proof-of-Vulnerability (PoV) serves as our oracle. We validate patches by re-running the PoV against patched programs. We say “likely correct” because patches might work through unintended mitigation rather than true fixes.
Consider these problematic “patches”:
- Recompiling C code with MTE or PAC on ARM to suppress PoVs
- Wrapping Java entry points in broad
catch(Exception)blocks
Our agents carefully avoid such mitigations.
Yet semantic correctness remains subjective—
which is why AIxCC provides optional test.sh scripts
as additional oracles for our patching agents.
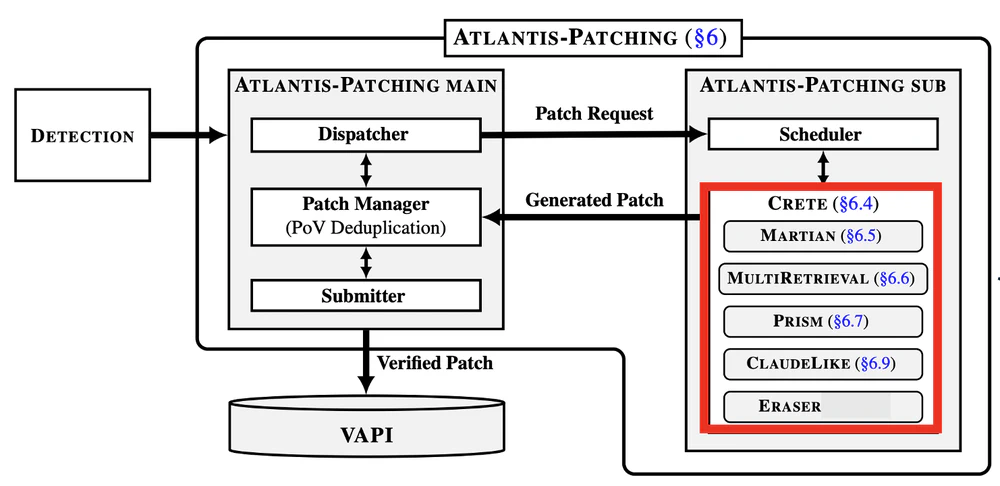
Building Specialized Agents. During preparation, we recognized a key insight: building one universally powerful agent is harder than building multiple specialized agents for specific tasks. This echoes the philosophy behind AlphaEvolve and AlphaCode.
Surprisingly, smaller models like GPT-4o-mini often outperformed larger foundation models and even reasoning models for our tasks. We speculate that its 8 billion parameters hit a sweet spot— large enough to understand code patterns, small enough to avoid overthinking simple fixes.
Practical Constraints on Scaling. Unlike AlphaCode’s massive agent scaling, we faced a practical bottleneck: validating patches in large codebases takes minutes if not hours (e.g., 10+ minutes for nginx). This forced Atlantis-Patching to limit itself to six agents, focusing on quality over quantity.
Theori took a radically different approach: purely static analysis, producing three correct patches without PoVs. This demonstrates LLMs’ remarkable ability to understand code semantics without runtime validation, which we’d like to explore further.
The scoreboard reveals the trade-off: Theori’s 44.4% accuracy yielded an Accuracy Modifier of 0.9044 ($1 - (1 - 0.4444)^4$), while our PoV-validated approach achieved 0.9999 ($1 - (1 - 0.9127)^4$).
Our CRS can generate patches without PoVs, but we deliberately chose not to—a strategic decision we debated extensively and validated through our internal benchmark.
Post-competition, we’re excited to explore PoV-free patching’s full potential.

L3. LLM 101: How to Babysit Jack-Jack?
During our CTFRadio interview, Yan mentioned that Shellfish had to babysit LLMs for their agents. The analogy resonates: LLMs are like Jack-Jack Parr from Incredibles— a superpowered baby with multiple, unpredictable abilities that even his superhero parents don’t fully understand.

Like Jack-Jack, LLMs have not one superpower but many, and we’re still discovering how to harness them effectively. We “gaslight” our LLMs into specific roles, telling them they’re “security researchers” or even researchers from Google DeepMind.
The Evolution of Prompting Techniques. Throughout the competition, we witnessed firsthand the rapid evolution of foundation models and prompting strategies. Early tricks like “I’ll give you a $200 tip” surprisingly generated longer, more detailed responses. Techniques multiplied: Chain-of-Thought (CoT), Tree-of-Thoughts (ToT), Self-Consistency (SC).
We tested everything and integrated what worked, like “Think step by step” prompts. Agentic architectures evolved in parallel: ReAct, Reflection, tool use, multi-agent systems, sub-agents— we adopted many (as shown above).
Managing Rapid Change. The pace of change in the LLM space is unprecedented. Every vendor claims benchmark supremacy, making it impossible to evaluate every new claim or technique.
Our solution: continuous empirical testing. We evaluate performance daily through CI using our internal benchmark, monitoring for sudden drops or improvements. (Shellfish even built an LLM agent specifically for this task!)
To avoid vendor lock-in, we built abstraction layers. LiteLLM serves as our proxy, multiplexing requests and responses across different LLM providers for each agent.
Handling External Dependencies. Since LLMs are externally managed services, Atlantis must handle various failure modes:
- Token limits exceeded
- Daily/subscription quotas hit
- Unexplained downtime or delays
We experienced all of these during the exhibition rounds and built resilience mechanisms accordingly.
L4. LLM-Augmented, LLM-Opinionated, and LLM-Driven
Atlantis employs LLMs through three distinct integration strategies, each with different levels of trust and autonomy.
LLM-Augmented: Extending Traditional Tool. In this approach, LLMs enhance traditional analysis techniques where conventional methods struggle with scale. Fuzzing tools integrate LLMs for:
Here, LLMs fill gaps where traditional techniques fail to scale to real-world software complexity.
LLM-Opinionated: Optimistic Suggestions. Tools like Testlang and Harness Reverser operate with calculated risk. LLMs provide likelihood-based suggestions that workflows treat as hints—similar to optimistic concurrency control.
When predictions are correct, the system benefits significantly. When wrong, we pay a performance penalty but maintain correctness.
LLM-Driven: Autonomous Navigation. Our most ambitious approach gives LLMs full autonomy. The MLLA agent and POC Gen in Java CRS autonomously navigate code repositories, generating “blobs”—inputs designed to trigger identified bugs from diffs or SARIF reports.
This strategy bets on LLMs having latent security intuition buried in their weights, allowing them to reason about entire codebases independently.
So How Well Did Atlantis Perform?
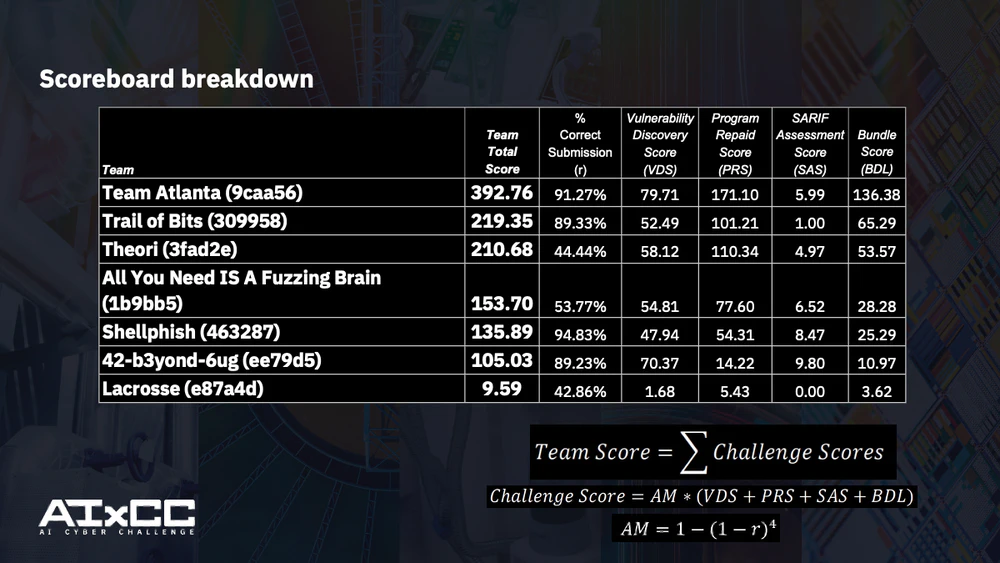
Atlantis dominated the scoreboard, earning top scores in nearly every category. Remarkably, we accumulated roughly the same total points as the second and third place teams combined.
While we’re still analyzing the complete dataset, early observations suggest our CRS excelled on certain challenge projects (like Wireshark) where other teams struggled. Our conservative strategy proved decisive: high accuracy in crash reports and patches yielded a near-perfect accuracy multiplier, while our strong bundle scores validated our careful approach to matching PoVs with patches and SARIF reports.
Real-World Bugs. Does this approach work in the wild? During the final, all competing CRSs collectively discovered 6 C/C++ bugs and 12 Java bugs in real-world software. Atlantis contributed 3 of each category, including a 0-day vulnerability in SQLite discovered during the semi-final.

What’s Next?
For a casual discussion of our journey and lessons learned, check out our CTFRadio interview:
Open Source Release. Our competition CRS code is publicly available, but the current system requires substantial infrastructure: Microsoft Azure deployment, Terraform, Kubernetes, Tailscale, and external LLM service dependencies.
To make Atlantis accessible to the broader community, we’re creating a streamlined fork that:
- Removes competition-specific APIs
- Runs on a single workstation via Docker Compose
- Includes a revised benchmark suite for standardized evaluation
Call for Collaboration. We’re launching continuous bug hunting on OSS-Fuzz projects. To sustain this effort, Team Atlanta is donating $2.0M (50% of our prize) to SSLab at Georgia Tech for:
- Ongoing research in autonomous security systems with LLM
- Expenses to continuously run Atlantis to open source projects
- Scholarship to PhD students and postdocs
Join us in advancing autonomous security research! And we are seeking funding for public research – OpenAI joined this effort to make donation to us along with the API credits.
Coming Soon.
- Technical Report: Detailed system architecture and findings (releasing in two weeks)
- Blog Series: Deep dives into specific CRS components and strategies
- Postmortem: Analysis of the final competition data and effectiveness of each techniques/CRSs


